
Our GraphQL endpoint currently generates faked-out employee data. Once we update our GraphQL resolver to query the Employee table in our database, we will have a truly full-stack implementation of just-in-time data loading (finally!).
Wondering how we got here? The first four posts in this series describe how to:
- Fetch data in batches with react-window’s infinite loader.
- Restore user scroll position.
- Render the data in windowed chunks with react-window and react-table.
- Set up the GraphQL endpoint for just-in-time fetching data; use Apollo Client to request and cache the data client-side.
The Implications of Cursor-Based Pagination
GraphQL docs recommend cursor-based pagination. With cursor-based pagination, we can query our GraphQL server for page of “count” number of rows, starting from the cursor.
Benefits
Cursor-based pagination definitely has some benefits. It’s more efficient than offset-based pagination, especially if you aren’t fetching the total count of items. In offset-based pagination, the database still has to scan all the records up to the offset plus count; it then discards the records up to the offset. As the offset increases, the performance of offset-based pagination suffers, whereas the performance of cursor-based pagination remains constant.
With offset-based pagination, the same bit of data could be skipped or returned multiple times if items were added or removed from the database. When using cursor-based pagination, data is always fetched from a fixed starting point (the start cursor), and it doesn’t matter if items added are removed before the start cursor. Think of it like a linked list: if you have a reference to a node in a linked list, adding or deleting nodes prior to that node wouldn’t affect that node’s “next” pointer.
Requirements
Cursor-based pagination also has some hard requirements around the cursor. The cursor must be unique, sequential (such as an auto-incrementing ID or a timestamp), and used as the sort key. For instance, if we were to use a createdAt column as the cursor, the returned rows must also be sorted by that createdAt column.
If you are using a column as a cursor and you want to sort by a non-unique column (name, email, etc.), you might want to abandon cursor-based pagination in favor of offset-based pagination. Otherwise, in order to make the cursor unique, you could try combining multiple columns into a cursor. (Read Chang’s excellent post on implementing cursor-based pagination for more on this.)
In my previous post, we did the initial work of setting up the GraphQL schema to support cursor-based pagination. In this example, we’ll make a createdAt column on the Employee table and use that column as our cursor. The createdAt column is unique, sequential, and a reasonable attribute to order by.
Setting Up the Employee Table and Record
To return actual Employee data, we’ll need to create an Employee table in our database. Let’s create an Employees table with some basic employee attributes (first name, last name, suffix, job title). Additionally, it will have a createdAt column. We’ll use this column as the cursor.
Next, let’s create an EmployeeRepository class, which is just an abstraction over the Employees table. An instance of this class can live on the GraphQL request context.
Updating the GraphQL Resolver to Use the Employee Table
Previously, the GraphQL resolver for rows just used faked-out data:
const getRowsConnection: QueryResolvers.GetRowsConnectionResolver = async (
parent,
args,
ctx
) => {
const startIndex = args.startCursor ? rowIdToRow[args.startCursor].index : 0;
const end = startIndex + args.count;
const endIndex = end < fakedOutRows.length ? end : fakedOutRows.length - 1;
const rows = fakedOutRows.slice(startIndex, end);
return {
rows,
pageInfo: {
hasNextRow: endIndex < fakedOutRows.length,
startCursor: fakedOutRows[startIndex].id,
endCursor: fakedOutRows[endIndex].id,
},
totalCount: fakedOutRows.length,
};
};
Our goal is to replace fakedOutRows with actual employee data from the Employee table. Given a cursor and a count, we want the next page of length “count,” starting from the cursor. We’re using the createdAt column as the cursor. In database terms, we want to count the number of rows with a createdAt value equal to or larger than the cursor. The SQL query for this looks like:
select * from "Employee"
where "Employee"."createdAt" >= %CREATED_AT
LIMIT 10;
I’ll use knex to simplify it a bit:
await this.table()
.orderBy("createdAt")
.where("createdAt", ">=", input.cursor)
.limit(input.limit
In the initial request for rows, we would not yet have a start cursor. In that case, we would just want to return the first “count” of employees. In SQL:
select * from "Employee"
orderBy “Employee”.”createdAt”
LIMIT 10;
Again, I’ll simplify with knex:
await this.table()
.orderBy("createdAt")
.limit(input.limit);
We’ll create a function on our employee repository that returns either the first chunk of rows (if we don’t yet have a cursor) or the chunk of rows immediately following the cursor:
rows = async (input: {
limit: number;
cursor?: string;
}): Promise<SavedEmployee[]> => {
return input.cursor
? await this.table()
.orderBy("createdAt")
.where("createdAt", ">=", input.cursor)
.limit(input.limit)
: await this.table()
.orderBy("createdAt")
.limit(input.limit);
};
Now that we have this repository rows method set up, let’s go back to the resolver.
In the getRowsConnection resolver, we can call the rows function with a limit of count + 1. This way, we’ll get the “count” rows to return, as well as the additional row (at count + 1). We’ll use this additional row to generate the end cursor — the unique identifier for the row that comes after the current chunk of data. If there exists an additional row, we can set hasNextRow to true; otherwise, hasNextRow will be false.
Putting this all together, the resolver looks like this:
const getRowsConnection: QueryResolvers.GetRowsConnectionResolver = async (
parent,
args,
ctx
) => {
const totalCount = ctx.repos.employees.count();
const rows = await ctx.repos.employees.rows({
...(args.startCursor && { cursor: args.startCursor }),
limit: args.count + 1,
});
return {
rows: rows.slice(0, args.count),
pageInfo: {
hasNextRow: rows.length === args.count + 1, // there is a row after the current
startCursor: rows[0] && rows[0].createdAt,
endCursor: rows[args.count] && rows[args.count].createdAt,
},
totalCount,
}; };
We are still returning the total count. If there are a lot of records, looking up the total count might be inefficient. When setting the total count for the Infinite Loader component on the front-end, we could always set the row count to one more than the current count, as long as there was still more data to load (hasNextPage is true).
const totalCount = hasNextPage ? rows.length + 1 : rows.length;
Also, be aware that the GraphQL documentation on cursor-based pagination recommends base64 encoding cursors. This would let the server encode additional information in the cursor.
Okay, We’re Done!
We now have a full-stack implementation of just-in-time data loading. Here’s a recap of the series, starting from the front-end table:
- We use react-window to “virtualize” the rows, rendering only enough elements to fill the viewport. This means less rendering work when the page is initially loaded and less memory being used for storing DOM nodes outside of the viewport.
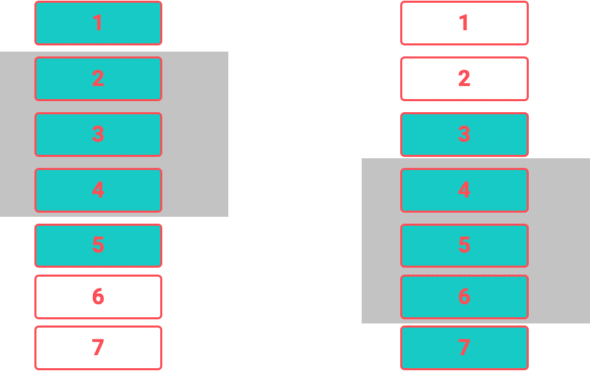
- In order to render these rows, we need to fetch the data for the rows. Instead of fetching all the data at once, we fetch it in chunks. We use Infinite Loader to fetch row data in chunks.

- We choose to do just-in-time data loading with cursor-based pagination. We query our GraphQL server for the page of “count” number of rows, starting from the cursor. We set up the server to be able to query the database for the next chunk of rows, given the count number of rows and a start cursor.
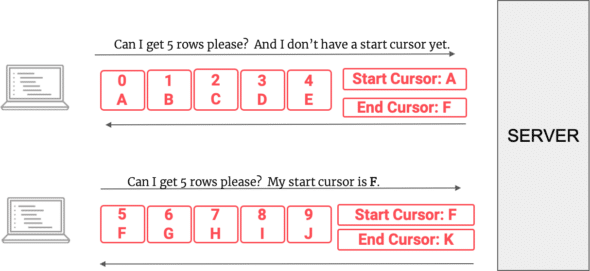
- Once we get the rows and the end cursor back from the server, we do some client-side caching. We want to keep the end cursor around until your next query (so we know where to start fetching rows from). We also want to keep the current rows around until they scroll out of view. We used Apollo Client for this; it does most of the work of keeping around the previous result (i.e., your previous end cursor, rows), merging the old result with new result, and keeping the client-side cache from getting too big. This way, we will always have the data we need in client-side state to render all of those table rows.
With that, we’ve successfully implemented just-in-time data loading. On the back end, we have a GraphQL server that supports pagination and can just-in-time load data from our database. On the front end, we have a table that indexes into that row data when rendering the table cells. When the user scrolls to a section of the grid that we don’t yet have data for, we’ll simply request that new row data from the server.
Happy scrolling!