
One of my favorite side projects has been building a web app for the golf league I play in. The React app allows me to enter scores, generate schedules, display results, and, most importantly to a competitive person, keep a record book.
The record book has all sorts of interesting stats for league members including career birdies made, career average to par, etc. Recently, I wanted to add a new record for consecutive holes with two putts or less, which is typically an indicator of a good score.
I decided I wanted to see if I could use Postgres to return a dataset that represented these streaks without having to do any comparisons or sorting in code.
After some Googling, it appears this is a common problem called the Gaps and Islands Problem. So, I set off to create a solution that showed me who has the most consecutive holes without putting three. Using Common Table Expressions (CTEs), I was able to create a solution that’s readable and efficient. Here are the steps involved.
1. Identify islands.
SELECT
members.id as member_id,
holes."number" as hole_number,
rounds.id as round_id,
scores.putts <= 2 as is_island,
LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) is null OR
(LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) <= 2) as is_previous_island
FROM scores
INNER JOIN holes on scores.hole_id = holes.id
INNER JOIN rounds on scores.round_id = rounds.id
INNER JOIN members on rounds.player_id = members.id;
The first thing this query does is simply return whether the current record is an island in the is_island column.
The second, more interesting, part of this query is leveraging the LAG window function. LAG allows me to return a second column that looks at the previous record in the set when partitioned and sorted in the same fashion. Note that you need to make sure you cover your base case here, which is the first record in the dataset. I did this with a NULL check.
2. Identify the starts and ends of islands.
Now that I have rows that tell me if the current row is an island and if the previous row is, I can determine the starts and stops of each island.
-- Step 1 pulled into a CTE
WITH islands_identified as (
SELECT
members.id as member_id,
holes."number" as hole_number,
rounds.id as round_id,
scores.putts <= 2 as is_island,
LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) is null OR
(LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) <= 2) as is_previous_island
FROM scores
INNER JOIN holes on scores.hole_id = holes.id
INNER JOIN rounds on scores.round_id = rounds.id
)
SELECT
islands_identified.*,
CASE WHEN islands_identified.is_island <> islands_identified.is_previous_island THEN 1 ELSE 0 END as is_new_island
FROM islands_identified;
This query simply uses the two columns I generated in the first query to determine if the current row is a switch from an island to a gap. If is_new_island is a 1, it’s a switch. If it’s a 0, it’s a continuation of an island or gap.
Here’s an example of the switches with islands and gaps called out:
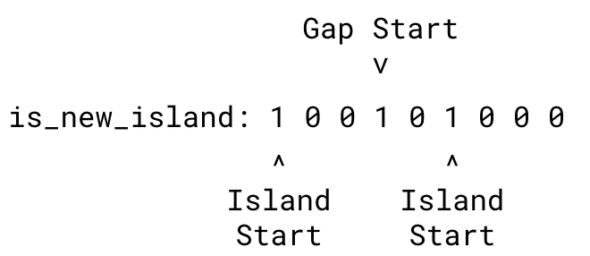
3. Create unique identifiers for each island.
This is the most clever part of the solution. Now that we have the starts and stops of islands identified, we need a way to distinguish islands from each other. Here’s the query to do just that:
-- Step 1 pulled into a CTE
WITH islands_identified as (
SELECT
members.id as member_id,
holes."number" as hole_number,
rounds.id as round_id,
scores.putts <= 2 as is_island,
LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) is null OR
(LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) <= 2) as is_previous_island
FROM scores
INNER JOIN holes on scores.hole_id = holes.id
INNER JOIN rounds on scores.round_id = rounds.id
),
-- Step 2 pulled into a CTE
islands_numbered as (
SELECT
islands_identified.*,
CASE WHEN islands_identified.is_island <> islands_identified.is_previous_island THEN 1 ELSE 0 END as is_new_island
FROM islands_identified
)
SELECT
*,
sum(islands_numbered.is_new_island) over (partition by islands_numbered.member_id ORDER BY islands_numbered.played_at ASC, islands_numbered.hole_number ASC) as island_id
FROM islands_numbered;
The cleverness is using the SUM aggregate to identify each island. It works because each switch from gap to island increases the SUM by one, which creates a unique identifier. Here’s the updated dataset, including identifiers:

You’ll notice that the gaps also get an identifier. You can ignore that because I’ll filter those out in the final query below.
4. Order and return the data.
The last part of the query is simply counting the records in each island, sorting them, and returning them. Here’s the entire query:
-- Step 1
WITH islands_identified as (
SELECT
members.id as member_id,
holes."number" as hole_number,
rounds.id as round_id,
scores.putts <= 2 as is_island,
LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) is null OR
(LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) <= 2) as is_previous_island
FROM scores
INNER JOIN holes on scores.hole_id = holes.id
INNER JOIN rounds on scores.round_id = rounds.id
),
-- Step 2
islands_numbered as (
SELECT
islands_identified.*,
CASE WHEN islands_identified.is_island <> islands_identified.is_previous_island THEN 1 ELSE 0 END as is_new_island
FROM islands_identified
),
-- Step 3
island_ids as (
SELECT
*,
sum(islands_numbered.is_new_island) over (partition by islands_numbered.member_id ORDER BY islands_numbered.played_at ASC, islands_numbered.hole_number ASC) as island_id
FROM islands_identified
)
SELECT
members.id as member_id,
COUNT(*) as island_length
FROM island_ids
WHERE island_ids.is_island = 't' -- Throw out all gaps
GROUP BY members.id, island_ids.island_id
ORDER BY island_length DESC;
And voila! I now have one row for every streak, where the first row is the longest streak. For a dataset of ~27,000 records, this query runs in roughly 20ms on my local machine.
I hope this is a straightforward way for you to understand the Gaps and Islands Problem so you can apply it in your next project.
Hi, thanks for that, it was very interesting.
I didn’t know about the LAG function.
I’ve just read the doc and it looks like you could have used a default value instead of making a case with null, that may accelerate the query (while you’re not concerned with performances in your case).
So instead of:
LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes.”number” ASC) is null OR (LAG(scores.putts) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes.”number” ASC) <= 2) as is_previous_island
You could have done:
LAG(scores.putts, 1, 0) OVER (partition by member_id ORDER BY rounds.played_at ASC, holes."number" ASC) <= 2 as is_previous_island