Article summary
Automation is good. Performing tasks manually is bad. Performing tasks manually is especially bad when the tasks are annoying. Let’s use a Ruby script to alleviate the pain of an annoying task.
Today’s annoyance: testing and working through the kinks of a brittle, ugly data import process.
We are planning to deploy Fedora Commons into our system soon. Fedora will help facilitate sharing data across a number of systems, including ours. Until now our system data has been stored in MySQL and on the filesystem; when we deploy Fedora, we also need to import the existing data into it. Future updates will go into Fedora as they happen.
The Original Process
We already have a script to import the data into Fedora, but before doing so, we’d like to test the import locally. Below is a picture that gives a rough idea of what must happen to run the test.
aption id=“attachment_95988″ align=“aligncenter” width=“1080″]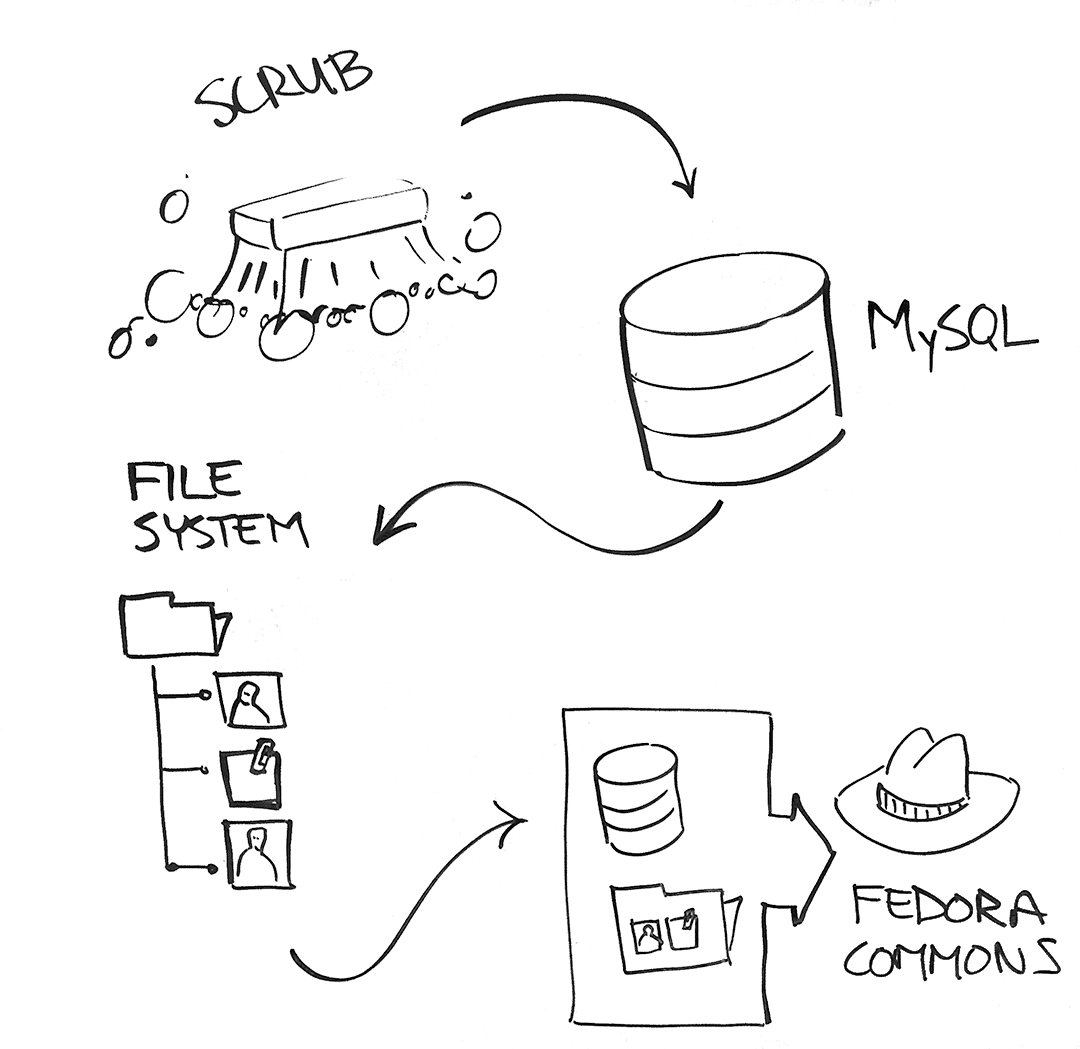 An annoying import process[/caption]
An annoying import process[/caption]
Here is a complete list of what’s going on, as the picture only shows the highlights:
- The local development database and file system are cleared of old data.
- MySQL data, which was previously saved from the production environment, is loaded locally.
- User avatar images and file attachments, which also came from production, are staged on the local filesystem.
- Rails migrations are run to ensure the the database schema is up-to-date.
- Our import script begins execution.
This is where things finally get interesting. At this point, someone can inspect the results from the import and correct for any hiccups that were encountered.
As you can see, none of the steps in the above list are particularly difficult, but they are numerous and annoying. And as we test and develop the import process, we need to rerun these steps. Rerunning these steps by hand is annoying, slow, and error-prone.
Wait. Did I just use the word “annoying”? Well! Let’s script away that annoyance.
The Script
I’ve created a gist of the script and embedded it at the bottom of this post for quick reference. Here are some highlights:
- The script runs in the context of a Rails application. I found it helpful to double check this every time the script runs, as a mistake here could lead to unanticipated destruction — a small amount of work for a large amount of safety.
- I define a high-level method for each high-level task. This way I can easily remember what happens in the script (in fact, it helped in creating the above list). This keeps things tidy and makes it easy to shift things around.
- I define quite a few helper methods. Each helper took me mere moments to create, but paid off big time in terms of convenience and keeping things minimal.
- I have run this script about a dozen times at this point and have not needed to think about the steps since I wrote them.
And most importantly: I composed the majority of this post while the script was running in the background. Automating this annoying task has increased both my efficiency and throughput.
Hooray for automation!
#!/usr/bin/env ruby
require 'pathname'
module TestProductionDataImportToFedora
module_function
def go(dir)
source_dir = find_source dir
validate_running_from_rails_root
reset_everything
load_mysql_data(source_dir)
stage_avatar_data(source_dir)
stage_project_content(source_dir)
migrate
import_into_fedora
end
def find_source(source_dir)
source_dir ||= Pathname.new(Dir.home).join('Desktop', 'production')
source_dir = Pathname.new(source_dir)
if !source_dir.exist?
puts "I couldn't find your source directory [#{source_dir}]!"
exit 1
end
source_dir
end
def validate_running_from_rails_root
if !(File.exist?('Rakefile') && File.exist?('config/environment.rb'))
puts "It doesn't look like you're running this from the Rails root directory! Please run this task from there."
exit 2
end
end
def reset_everything
task 'Resetting all local data in the development environment.' do
%w[ db:drop db:create file_store:clear fedora:clean ].each do |rake_task|
rake rake_task
end
end
end
def load_mysql_data(source_dir)
mysql_archive = find_file(source_dir, 'mysql')
task "Loading mysql data from [#{mysql_archive}]." do
run "gunzip -c #{mysql_archive} | mysql awesome_database"
end
end
def stage_avatar_data(source_dir)
avatar_data = find_file(source_dir, 'avatars')
avatar_directory = 'public/uploads'
task "Staging avatar data from [#{avatar_data}]." do
run "mkdir -p #{avatar_directory}"
run "tar xfj #{avatar_data} --directory=#{avatar_directory}"
run "mv #{avatar_directory}/{production,development}"
end
end
def stage_project_content(source_dir)
project_content = find_file(source_dir, 'uploads')
project_content_directory = 'uploads'
task "Staging project content from [#{project_content}]." do
run "mkdir -p #{project_content_directory}"
run "tar xfj #{project_content} --directory=#{project_content_directory}"
run "mv #{project_content_directory}/{production,development}"
end
end
def migrate
task 'Migrating the database to the newest schema.' do
rake 'db:migrate'
end
end
def import_into_fedora
task 'Running the Fedora data import. Good luck!' do
rake 'fedora:import'
end
end
def find_file(source_dir, name)
Dir["#{source_dir}/*"].find do |file| file.match(Regexp.new(name)) end
end
def task(message)
puts message
yield
puts "Done."
puts
end
def run(command)
environment = { 'RAILS_ENV' => 'development', 'LOG_FEDORA' => 'yesplease' }
puts "Running [#{command}]."
system environment, command
end
def rake(rake_task)
run "rake #{rake_task}"
end
end
TestProductionDataImportToFedora.go(ARGV.first)