Article summary
C’s design limits functions to directly returning at most one value. Unfortunately, there are many cases where returning more than one makes sense — returning a data buffer and its size, returning either a success code and data requested or an error code, splitting a tree node into two, etc. Making returning multiple values awkward has likely led to many security problems over the years, when people forget to track (or check) sizes associated with buffers. There still isn’t an obviously correct way to return multiple values, just a couple of methods with different trade-offs.
Three Common Techniques
The most common method involves mutation: The function returns one value, and additional values are written into pointers that were passed in by the caller. (They may or may not be NULL-checked.) While there are conventions for this, such as returning a status code and writing the result(s) into parameters, the language standard has no opinion. Passing around pointers to return values through can be a source of subtle errors, and (along with pointer arithmetic) also complicates static analysis.
Another option involves tuples or tagged unions — returning a struct by value, with multiple values nested inside. It may be two or more values of known type (a tuple), or it could pair an enum indicating the result’s runtime type with a union that stores the overlap of all possible result types (including tuples). In the ML family of languages (OCaml, SML, Haskell, …), the combination of structural pattern matching and Hindley-Milner type inference makes this a concise and convenient way to do error handling (and largely eliminates dealing with NULLs), but it’s uncommon in C, perhaps because it’s perceived to be an expensive operation. This may not be as true with modern hardware and compilers, but it is still a bit verbose. (This kind of boxing is also necessary to return an array by value. C will otherwise return it as a pointer, likely referencing memory that has been overwritten by newer stack frames.)
A third option involves mutation of global values. This is far worse from a dataflow clarity standpoint, but can be a reasonable choice for generated code when compiling to C. All the functions in a module mutate one or more of a set of shared variables, which collectively behave like registers for a virtual machine.
These approaches can also be combined: returning a type enum and writing a pointer to a struct of the appropriate type into a pointer parameter, for example.
Benchmark Comparison
I’ve written some benchmark code that compares these methods. There are N functions that take a long int and return it divided by two, as well as an enum value indicating whether it’s even or odd. (While rather contrived, this emphasizes the overhead of the return mechanism over the function’s work.) There are also two functions that return nothing and return the divided value, to show the runtime impact of returning multiple values at all. Multiple values can also be returned via longjmp (to implement backtracking), but it is difficult to make a small benchmark where the costs of setjmp/longjmp don’t completely overwhelm the costs of a tiny example function, so I’ve left it out.
These graphs show timing for 9 benchmarks, run at -O0 and -O2 on three different hardware platforms. (Click each graph to see a larger version.)
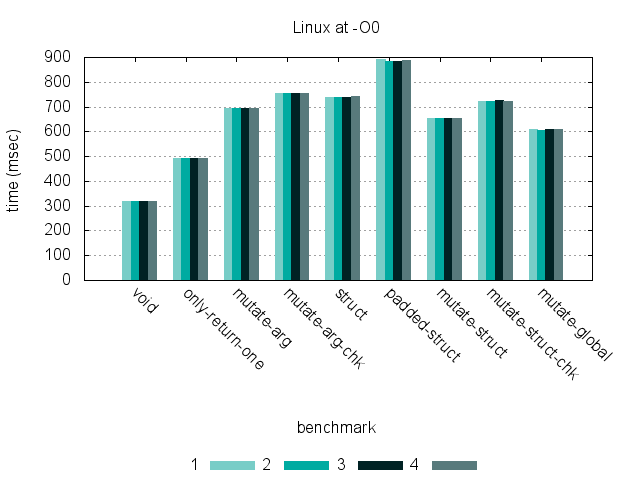
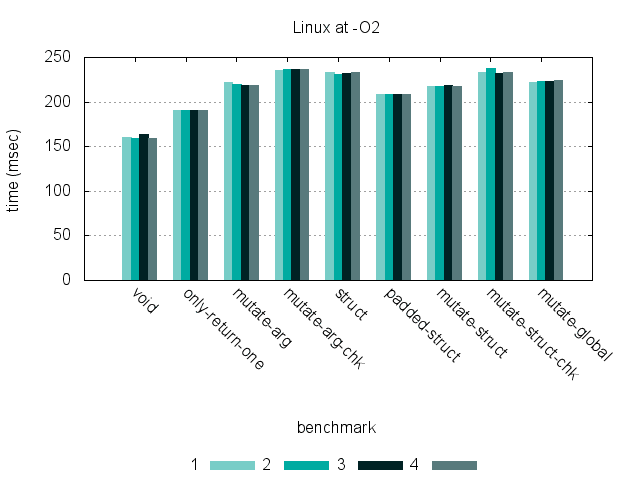
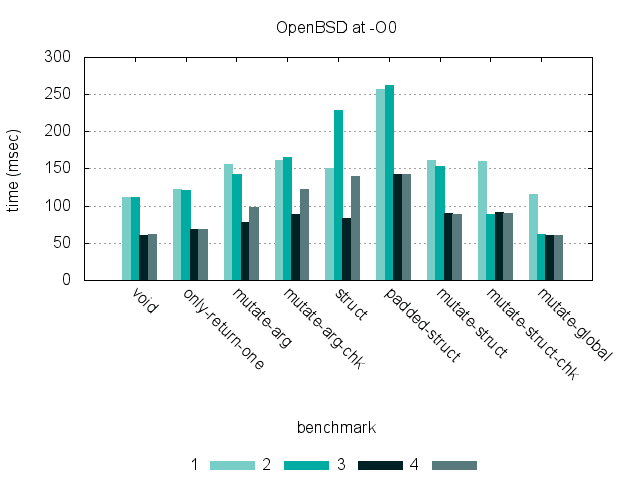
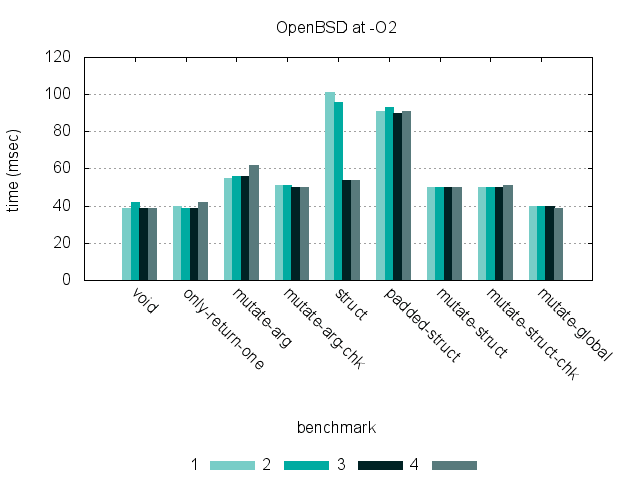
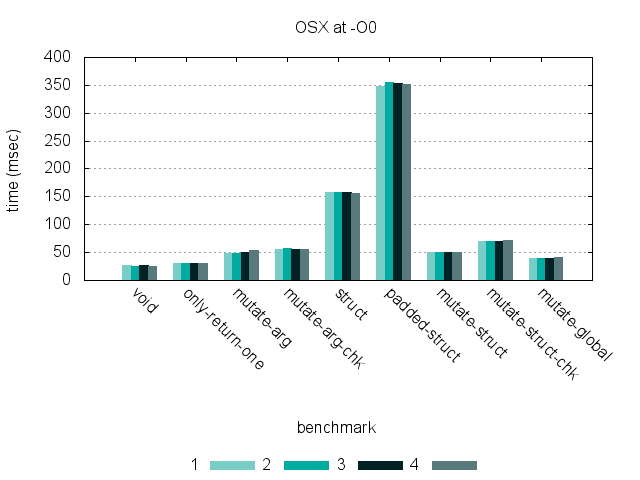
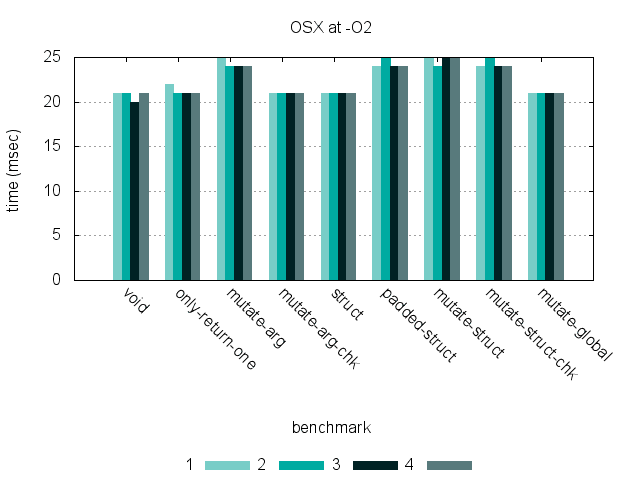
Benchmarks
These first two return zero and one value, to show the cost of returning multiple values at all.
- void – Right-shift the input, don’t return anything.
- only-return-one – Right-shift the input and return it.
The rest return two values, by various means.
- mutate-arg – Return whether the input is odd or even, and return the argument right-shifted by writing into a pointer argument.
- mutate-arg-chk – Same as mutate-arg, but check that the pointer is non-NULL first.
- struct – Return a struct value with odd/even and the right-shifted input.
- padded-struct – Same as struct, but add unused space around the struct to show the cost of returning larger struct values.
- mutate-struct – Dereference a struct pointer and mutate both its fields.
- mutate-struct-chk – Same as mutate-struct, but check that the pointer is non-NULL first.
- mutate-global – Mutate global variables, instead of returning anything.
Computers
The hardware platforms are the following three computers:
-
OSX: A “15-inch, late 2011” MacBook Pro:
Darwin sonic-the-hedgehog-the-laptop.local 11.4.2 Darwin Kernel Version 11.4.2: Thu Aug 23 16:25:48 PDT 2012; root:xnu-1699.32.7~1/RELEASE_X86_64 x86_64 -
OpenBSD: A fairly low-powered 32-bit x86 computer, being used primarily as a firewall:
OpenBSD oolong 4.9 GENERIC#671 i386 -
Linux: A Model-B Raspberry Pi running Raspian Linux:
Linux raspy 3.6.11+ #474 PREEMPT Thu Jun 13 17:14:42 BST 2013 armv6l GNU/Linux
Since there is a fairly wide gap performance-wise between these three computers, this shouldn’t be considered a meaningful comparison of the raw speed between the OSs.
Analysis
While returning a struct by value is significantly slower than the other methods at -O0 on an x86-64 processor, compiling at -O3 eliminates most of the overhead. Regardless of optimization, there is much less of a difference between approaches on an ARM processor — this is likely due to differences in the ARM ABI that make returning non-word values such as structs less expensive. (Also, returning a struct with a few additional unused fields has very little impact on the runtime for either platform.)
These results reinforce that writing first for clarity, rather than efficiency, tends to be a safe bet. Code written less clearly to wring additional speed out of today’s hardware may lead to little improvement over clearer code on future architectures. Also, assumptions about what techniques are too costly to use should be revisited as hardware and platforms evolve. Last decade’s awkward workarounds for performance problems may no longer be necessary.
Is your code available for download and experimentation?
It should be up in a day or two.
You really should post the source code used for the testing along with the results.
It will be, in a few days.
Funny, just re-hit this page looking for the source.
you’ve got to pick different graph colors, I’m “color deficient” and I can barely read those graphs even when I enlarge them.
Other than that, very interesting.
I primarily deal in enterprise software and this is what we tell developers and designers all the time. Aim for clarity, and trust the compiler to optimise for you.
The ternary operator should be removed from the tests. You are including a branching mechanism where the “void” and “return one” tests do not involve any branching.
I suspect the cost of branching is making the other tests appear more expensive than they really are.
I tried it last night and it did not seem to have much impact. You’re right that it may be adding noise, though. I will update the benchmarks. Thanks.