Article summary
When working with large language models (LLMs) to build an AI agent, one important challenge is dealing with their inherent non-deterministic outputs. LLMs, by design, can produce different responses to the same input, making it difficult to reliably assess their performance. As a result, having a framework to measure the behavior and effectiveness of your AI agent can be extremely helpful.
Evals: Unit Tests for AI Agents
Evals can be thought of as unit tests but for AI agents. Instead of testing deterministic outputs they evaluate behavior and outputs based on criteria relevant to your use case. Like unit tests, they help make it safer to make changes while creating quicker feedback cycles. Evals are particularly useful for:
- Identifying performance gaps: Evals surface areas where your agent may struggle.
- Measuring improvement: They provide a baseline metric to iteratively improve upon.
- Catching regressions: By running evals consistently, you can detect when a change negatively impacts performance.
Unlike the assertions that you’d typically see in tests, it is common for evals to measure more ambiguous characteristics. Some examples include:
- Similarity: Does the agent provide a response with a similar sentiment to that of an expected response?
- Coherence: Does the agent’s response make sense in context?
- Relevance: Is the response aligned with the user’s goal?
- Tone: Does the agent communicate in the expected manner?
By using an eval framework, you can systematically test these different aspects of your AI agent, identify where it’s failing, and focus your improvements in a targeted way.
Build An Eval Framework
You could use many different tools to help you evaluate your agent’s performance. Some examples include: Open AI Evals and Langfuse. Alternatively, you can build your own eval framework. It’s quite straightforward and an excellent way to understand how the evaluation process works and tailor it to your specific needs. Here’s how you can do it:
Note: I was heavily inspired by this tweet from Matt Pocock.
In this example, we’re looking to evaluate a basic chatbot agent: question in, answer out. Let’s start by creating an eval runner.
type Scorer = {
name: string;
fn: (args: { output: string; prompt: string }) => Promise;
};
type EvaluationConfig = {
input: { prompt: string; scorers: Scorer[] }[];
task: (prompt: string) => Promise;
};
const average = (array: number[]) =>
array.reduce((a, b) => a + b) / array.length;
async function runEvals(config: EvaluationConfig) {
const { input, task } = config;
const scores: number[] = [];
for (const { prompt, scorers } of input) {
// Run the task (agent)
const output = await task(prompt);
// Run all of a prompt's scorers
const results = await Promise.all(
scorers.map(async (scorer) => scorer.fn({ output, prompt }))
);
// Calculate the combined score as an average of all scores
const avg = average(results);
scores.push(avg);
}
// Calculate the final score as the average of each prompt's score
const score = average(scores);
console.log(`Score: ${score}`);
}
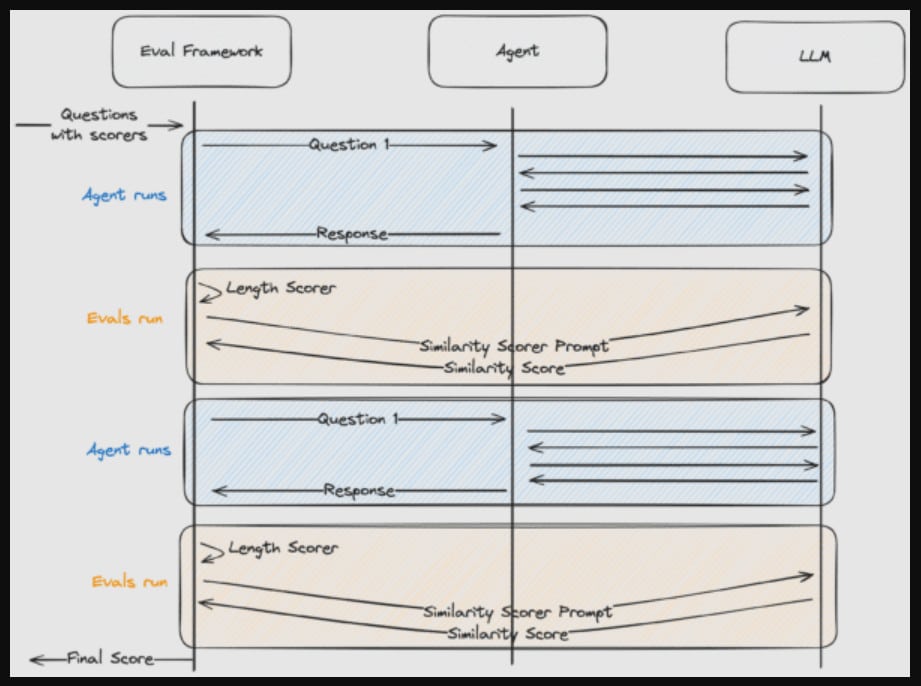
As you can see, the input into the runner is a list of prompts and scorers. Prompts, which are often just questions, are simply the input to the agent. Scorers are functions that evaluate the response of the agent based on the prompt. To align with what we’ve established in the runner, the scorers will accept the prompt and the output. They will return a number from 0 to 100.
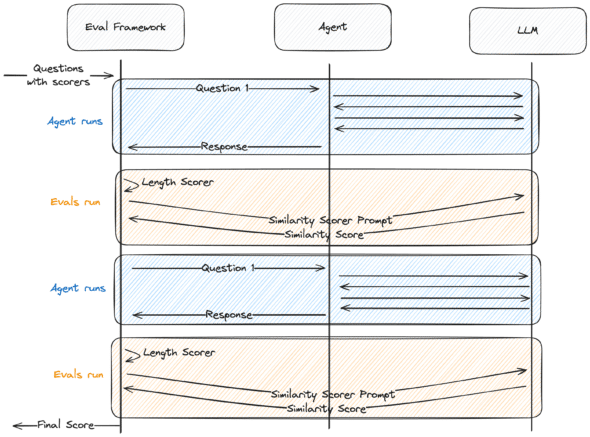
Scorers can be as sophisticated or as simple as you’d like them to be. Some scorers may be basic one-line functions, while others may involve their own LLM calls. We’ll create two scorers.
Scorer 1
This first scorer is a simple one. Its job: consider the length of the output. If the length is greater than 20 return 100, otherwise return 0.
const LengthScorer: Scorer = {
name: "Length Scorer",
fn: async ({ output }) => {
return output.length > 20 ? 100 : 0;
},
};
Scorer 2
This second scorer’s job is to judge the similarity of the output compared to an expected output. It’s a bit more involved than the first since it has its own LLM call, but the inputs and outputs of the scorer remain the same. We’ll write a prompt that explains the comparison we’d like to make and the output we’d like to receive. We’ll inject the actual and expected outputs. Then we’ll invoke the LLM, passing the full prompt.
const PROMPT = (output1: string, output2: string) => `
Your task is to analyze the content, context, structure, and semantics of the \
provided outputs and assign a similarity score between 0 and 100.
- A score of 100 indicates that the outputs are identical in meaning, content, \
and structure.
- A score of 0 indicates that the outputs are entirely dissimilar with no \
overlap in meaning or structure.
- Intermediate scores reflect partial similarity, with higher scores for \
closer matches.
Guidelines:
Focus on semantic similarity (meaning and intent).
Account for contextual overlap (relevance and usage in context).
Consider structural similarity (format and organization).
Value meaning over wording (paraphrased responses).
Input:
Output 1: ${output1}
Output 2: ${output2}
Provide only a valid json object with the score and an explanation. \
For example, if you think the outputs are 80% similar, return '80'`;
export const createSimilarityScorer = (expectedOutput: string): Scorer => {
return {
name: "Similarity Scorer",
fn: async ({ output }) => {
const llm = getModel();
const result = await llm.invoke([
{ role: "user", content: PROMPT(output, expectedOutput) },
]);
return Number(result.content)
},
};
};
Lastly, we’ll utilize our runner. We can add a couple prompts and configure some scorers.
runEvals({
input: [
{
prompt: "What is the Truman Show about?",
scorers: [
LengthScorer,
createSimilarityScorer(
"The Truman Show is a satirical drama about a man who discovers his entire life has been a staged reality TV show broadcast to the world without his knowledge."
),
],
},
{
prompt: "What is the fastest mammal?",
scorers: [
LengthScorer,
createSimilarityScorer(
"The fastest mammal is the cheetah, capable of reaching speeds up to 70 mph (112 km/h) in short bursts while chasing prey."
),
],
},
],
task: async (question) => {
const response = await Agent.invoke({ question });
return response;
},
});
Now we can run the eval script to see our agent’s score.
% npx tsx run-evals.ts
Score: 83.45%
And that’s all there is to it. I’ve found this framework to be very flexible. This example is intentionally minimalistic so I’d recommend adding some of the following things:
- An HTML reporter with more robust info to make the output easier to review
- Scorer explanations that can give insight into why something was scored a certain way (hint: ask the model to return a score and an explanation)
- Internal state evaluations useful for debugging the internal behavior of the agent.
Did I miss anything? Let me know!