
Prompting a language model might feel like casting a spell — say the right words, and something magical happens. But like any good spellbook, it helps to understand the principles behind the incantation. If you want an LLM to produce something useful, the burden is on you to wield context with intention.
Before you hit “send” on your next prompt, ask yourself these three questions. Each one will help you unlock better results.
1. How rigid are my requirements?
Not all prompts are created equal. Some are like open-ended brainstorming sessions: “Give me some ideas.” Others are more like contracts: “Generate a React component that matches this exact pattern.” The trick is knowing where your need falls on that spectrum.
I picture this as a sliding scale — on one end, there’s total flexibility. On the other, there is complete precision. The more rigid your expectations, the more context you need to provide. That might mean examples, style guides, or even dummy data. If the LLM has very little room to guess, don’t make it guess.
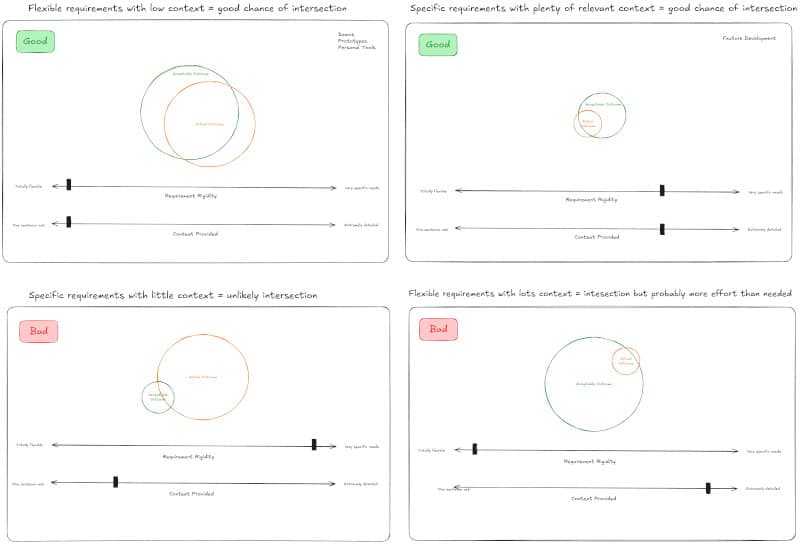
When I’m vague with a vague task, I usually get back… something vague. But when I care deeply about the outcome, I treat the prompt like a spec. More context leads to better alignment.
2. When do I want to provide context?
There are two common strategies for prompting:
- Iterative prompting: Fire off a rough idea, then refine it through back-and-forth. Great for exploration.
- Front-loaded prompting: Write one carefully crafted prompt that includes all the needed context. Great for execution.
You can’t escape providing context — the only question is when you do it. If you’re unsure what you’re trying to build or want to explore options, start small and iterate. But if you’ve already got a vision in your head, invest in a strong, detailed prompt. This is something that you can do manually if you’d like or you can ask the LLM to generate a plan for you to review. This is where prompt tools like Bivvy, AI Dev Tasks, or TaskMaster shine.
Personally, I find this question reframes my use of LLMs from “help me figure this out” to “help me build this thing.” The former is more of a thinking partner. The latter is more like a tool. Both are useful — just don’t mix them up.
3. What is quality of the context the context that I have available?
When using tools like Cursor, or Claude Code context doesn’t live only in your prompt. It also lives in your codebase. The structure of your project can make or break how effectively an LLM can help.
Let’s break it down into three common scenarios:
Brand New Codebases
Greenfield projects are a blank canvas. There’s freedom to experiment, invent new patterns, and mold things in AI-friendly ways. Establish conventions early that an LLM can learn from.
Well-Organized Codebases
In small to medium codebases with consistent patterns, LLMs can perform surprisingly well. They can understand how things are structured, and make coherent suggestions. This is the sweet spot for code gen — provided you’re continuing to make quality changes and are leveraging rules effectively.
Messy Codebases
In these codebases, LLMs will usually struggle. Due to unclear practices and conventions, it will naturally be harder to generate high quality code. There is still a lot of room to use LLMs to investigate, trace, and explain functionality within the app.
Prompting with Purpose
Much like programming, prompting is a strategic art. The best results come when you approach the process with clarity — know your constraints and use context effectively. Think of each prompt as an opportunity to shape how the LLM thinks, not just what it outputs. Being intentional pays off — in fewer rewrites, faster iteration, and outputs that actually move your work forward.
Great topic! You can ask an LLM to evaluate your prompt, and usually to save that request across sessions. For example, with Big AI Provider it will mention when my prompts are unusually good or poor on a 1-10 scale as I asked it to do. This helps train me on writing better prompts.