Frontier AI models today are incredibly powerful. They excel not just at writing bits of code but also at assisting with planning and architecture. They are also increasingly expensive. Early on in the AI era, developers had the luxury of tossing around tokens willy-nilly, delegating any task imaginable. Today, reality is starting to catch up. Token limits are regularly hit, and well before a refresh.
Learning how to use AI effectively has been a major focus. Now, we also need to learn how to use it more efficiently. I’ve been experimenting with local models, and wanted to see how viable they could be when used alongside a frontier model.
Limitations of Local Models
Local models have limitations, especially when running them on your own computer. If you look up folks who’ve been using them, you’ll find some people who’ve had a lot of success. They’ll claim they’re running models that come close in performance to frontier models. You’ll then find that those same people are running these models on thousand-dollar GPUs.
If you’re running one on your laptop, you’re going to run into those limitations much more acutely. I’m working on a MacBook Pro with an M4 Pro chip and 48GB of memory. That’s nothing to scoff at, but the difference in quality between a frontier model and a locally run one is significant. They are capable, as we’ll go over, but you can’t rely on them to do heavy lifting.
I experimented with Qwen3.6-27B through llama.cpp and Pi. I spun up boilerplate for a small full-stack web app and ran it through the gauntlet, seeing how it handled tasks of varying complexity. It worked a bit more slowly, like the frontier models of yesteryear (2024), but effectively on smaller chunks of work.
It sometimes got stuck, caught in loops, and made dumb mistakes, but I found it useful with a little bit of handholding. For more complex tasks, I felt like it spun its wheels too much and deferred to Claude when it got stuck.
Pairing with Frontier Models
Frontier AI models are increasingly equipped to handle large-scale planning. They can assist in work definition, issue creation, and triaging those issues. These are the kinds of tasks that – for now – should remain in the hands of the frontier models.
But they don’t need to be responsible for every little bit of work. If we want to be smarter with our tokens, we can find the most complex tasks that we’re confident our local model can handle, and have our more powerful models work down to that level.
For science’s sake, I ran an experiment. I wanted to create a simple blog app that allows a user to a) view a list of posts and b) submit a post. I used Opus to plan the entire thing. It set up two folders, each containing the foundation for a simple React/Express app: one for Opus to work on, and one for Qwen.
I had it include the same AGENTS.md file in each. I also had it write identical lists of features in separate markdown files. Once the boilerplate was up and the work was ready, I had my local model and Opus get to work on their projects.
I was pretty impressed by the results. Both took under 10 minutes, but Qwen actually finished a minute or so faster (Opus asked lots of questions, probably not a bad thing). Opus produced higher-quality, more maintainable code. Qwen’s version could benefit from a little bit of cleanup, but it was far from poor.
On the flip side, I thought that Qwen did a nicer job with the styling (see below). It also got bonus points for displaying timestamps. Overall, both produced output that I’d consider acceptable. Both successfully implemented all of the features, and both apps worked without issue on the first try.
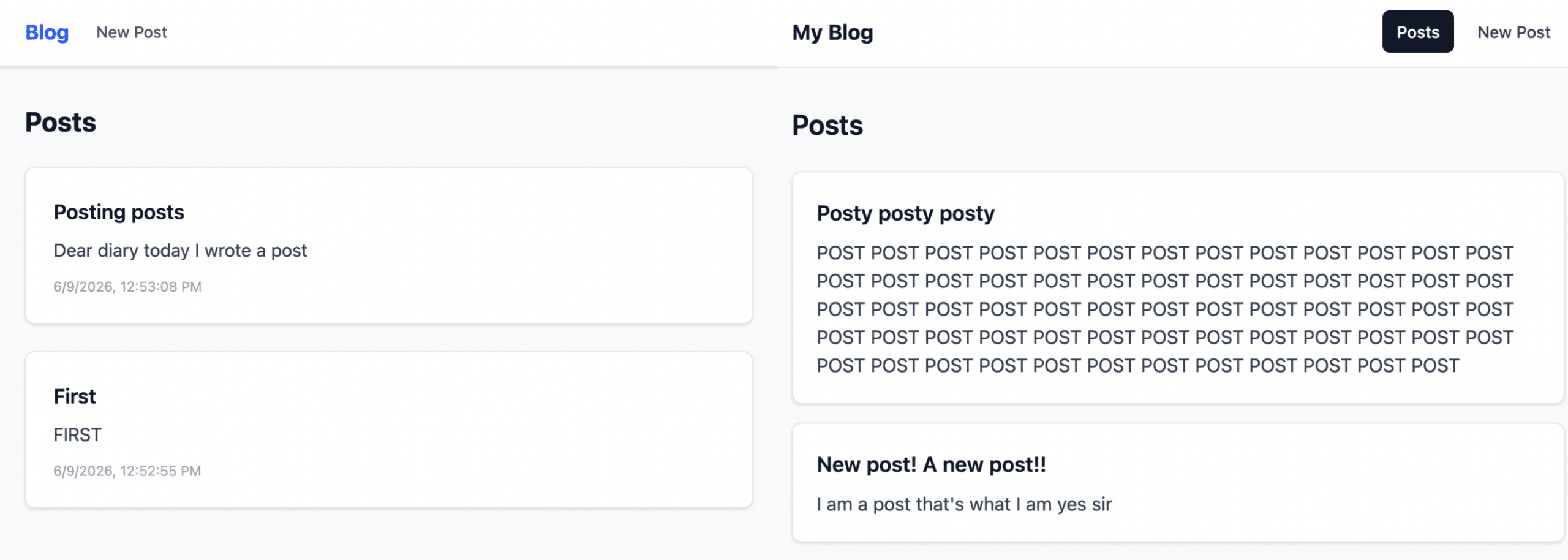
Most relevant: Opus used 5.5k input tokens and 37.1k output tokens, estimating a cost of $4.08. The local model did almost the exact same work for free.
My takeaway? If I’m trying to be careful with my token usage, I’d feel pretty comfortable using a hybrid approach. A frontier model to handle planning, architecture, and creating workable feature definitions. A locally run model to pick up and run with the defined work.
Finding the Sweet Spot
Finding the level of complexity in the tasks you can hand off to your local model can be tricky. It’s highly variable, depending on which local model you’re able to use. Take some time to experiment. Play around with different chunks of work, and get a feel for how much direction your local model needs. Get a sense of where it starts to struggle, so you know exactly what your frontier model needs to handle.
If you’re limited to running one of the weaker models, you may only be able to have it assist with simple tasks. This can still be a place to practice efficiency. Try to take note throughout the day of how many small bits of work you use AI for. Writing small individual functions, a few unit tests, etc., does not always need a state-of-the-art model.
A Hybrid Approach
Locally run models are still in their infancy and are a long way from being a viable replacement for frontier models. They can still be useful, and it’s worth learning how you can use them in tandem with more powerful models. Given the increasing price of frontier models, it can pay to learn how you can use them in development.