
Article summary
At Atomic, we’re always looking for tools that can improve how we work with clients and manage our internal processes. While most people think of Cursor as a coding tool, it’s one of the most effective knowledge management platforms I’ve used. A lot of my work involves drafting documents and parsing dense information (especially in long, formal sales processes that involve lengthy RFPs).
I first started experimenting with using ‘generation 1’ LLM-powered applications like ChatGPT and Claude’s desktop apps, but I’ve since found that Cursor’s combination of file organization, flexible AI integration, and familiar Git workflows has really leveled up my ability to produce general tools to routinize complex tasks.
The Knowledge Management Challenge
Traditional knowledge management tools are helpful but have some issues. Information gets siloed between different teams and projects, making it difficult to maintain and update documentation when we need it most. So often we’d create artifacts in spreadsheets, document files, Miro boards, etc. and then those documents get lost in a haystack and never updated.
I’m pretty sure this is a common problem. Important insights get buried in email threads, project learnings don’t transfer between teams, and documentation becomes outdated the moment it’s written.
File Organization Beyond Code
Cursor is a forked version of Visual Studio code that has been enhanced with the ability to interact with an LLM to modify the files you’re working with. It’s designed for programmers first. I started my career as a developer using Integrated Development Environments (IDEs) like Visual Studio, so when I first approached using Cursor, it felt very natural to me.
What I discovered early is that Cursor is a powerful way to organize files, and it’s not just for code. The same folder structures and search capabilities that make it excellent for development work equally well for client projects, meeting notes, and process documentation. I’ve started organizing our Atomic Object documentation using the same hierarchical approach we use for software projects.
The key insight is treating knowledge work with the same systematic approach we use for code. Clean folder structures, consistent naming conventions, and logical groupings make a huge difference in findability later.
LLM Flexibility and Comparison
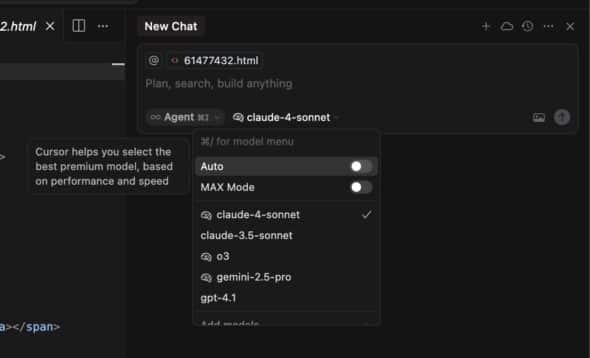
One of Cursor’s biggest advantages is that you can use any LLM you want. You can also generate output from multiple LLMs to compare results. Different models have different strengths—Claude excels at analysis and structured thinking, GPT tends to be better for creative writing and brainstorming, and o3 is great for reasoning tasks (note: I’m sure as soon as this post is published, the previous thoughts will be out of date).
I’ve found it valuable to create templates that leverage different LLM strengths for specific knowledge tasks. For client discovery sessions, I use Claude for synthesizing research. For proposal writing, GPT can sometimes provide better narrative flow.
Meta-Programming Your Knowledge Work
When I first started, I wrote prompts myself, but I found a better way that is likely obvious in retrospect: use the LLM to generate prompts themselves. Instead of starting from scratch each time we need to run a project retrospective or prepare for a client discovery session, we can ask the AI to create prompts tailored to our specific situation.
I’ve built up a library of prompt generators for common knowledge tasks. The AI helps create better questions for client interviews, generates frameworks for analyzing project outcomes, and even suggests a structure for complex documentation projects. Some other tips I’ve found useful:
- Instead of typing what you want in the prompt, record yourself describing the prompt you want and provide the transcript to the LLM.
- Save prompts in aptly named markdown files within your ‘codebase’ of tools.
- Adjust the prompt using the LLM, too.
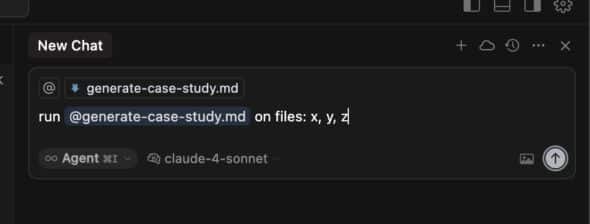
- Chain prompts together and run them by referencing them in cursor, like below:
Version Control for Ideas
Consider using the Git integration for version history—not just for code, but for ideas, decisions, and documentation. If your team is comfortable with code repositories, it’s a way to version control knowledge output. It also helps snapshot LLM output, which, at the best of times, is squirrely and at the worst completely unpredictable.
Working with Non-Text Files
Cursor only handles text files, but there are straightforward ways to work around this limitation. I’ve found tools like pdf2markdown and Claude can convert PDFs to markdown, describe images in structured text format, and transform spreadsheets into readable data tables (e.g., Sheets can export as .csv or .html, which Cursor can read). The key is building consistent workflows for these conversions.
The constraint can actually help. It forces everything into text format, making knowledge more searchable and accessible across different tools and team members. It also future-proofs our documentation against software changes and drives you, the author, to be more discerning about what you’re providing your AI toolchain.
Context Window Management
Understanding the differences between Cursor’s context window and the LLM itself has important ramifications for how much information you provide. My experience is that less information that’s better curated makes the output more predictable and useful.
I’ve learned to prepare context thoughtfully rather than dumping everything into the window. This means summarizing key points, highlighting the most relevant background information, and being selective about what details actually matter for the task at hand. For example, if you want your agent to follow the writing style of past documents, provide a few that are exemplary, not the entire corpus of all past documents you’ve ever written.
Maintaining Quality and Consistency
If you want to maintain any reasonable level of quality, you, the human, HAVE to review LLM-generated content. I’ve learned to balance automation with human oversight—the AI is excellent at first drafts and structure, but human taste and experience are still crucial for accuracy, tone, and strategic thinking. Our industry as a whole has a big challenge on its hands: how do we help less experienced people use these tools while maintaining quality? I haven’t heard a compelling answer to that, yet.
Challenges and Limitations
Traditional tools are still better for many tasks. Cursor IDE isn’t ideal for highly visual documentation, real-time collaborative editing, or situations where you need extensive formatting and layout control. LLMs do an acceptable job formatting Markdown and can create some (ugly) charts, but that’s generally not good enough for a finished product, so I always take the raw text output and manually bring it into a final polishing stage, after editing.
Privacy and security considerations are also important: at worst, working with an LLM is like typing into a Google search, so you must be extremely careful to establish guidelines for how to use the tools to avoid leaking sensitive data.
The cost implications of increased LLM usage can add up, especially for larger teams. We track usage and expenses to avoid big surprises, while still getting value from the platform.
What’s Next
The combination of systematic file organization, intelligent AI assistance, and version-controlled collaboration has made my job easier, made rote tasks more fun, and generally helped my productivity. Our team is finding faster access to relevant information, better consistency in our documentation, and more effective knowledge transfer between projects.
I’d love to hear about your knowledge management challenges. What problems are you trying to solve with documentation and information sharing in your organization? How do you currently handle the challenge of making institutional knowledge accessible when your team needs it most?