Article summary
- Part I: The Problem (Why Current AI is Like Digital Concrete)
- Part II: The Vision (What Self-Improving Systems Could Look Like)
- Part III: The Technical Foundation (How This Actually Works)
- Part IV: Reality Check (What Could Go Wrong and What We're Learning)
- Part V: Implications (What This Means for the Future)
A Thought Experiment: What happens when business software stops being a tool and starts being a team of specialists that actually learn?
Part I: The Problem (Why Current AI is Like Digital Concrete)
The Wild Idea: Software That Fixes Itself
Imagine your business software notices it’s been making mistakes that cost you customers. Instead of filing a bug report and waiting three months for the dev team to investigate, it just… fixes itself. It analyzes what went wrong, researches better approaches, writes improved code, tests it, and deploys the fix. And it does this all while continuing to run your business operations.
Sound crazy? Maybe. But we’re not talking about some distant sci-fi future. We’re talking about AI agents that don’t just run your business – they actively make it better, every day. So why isn’t this happening already? The answer lies in three fundamental limitations that make current AI systems about as adaptable as digital concrete.
The Memory Crisis: When AI Forgets Your Business
The Context Window Constraint
Here’s the fundamental constraint nobody talks about: current AI systems have hard memory limits. Even the most advanced language models max out around 2 million tokens of context. That sounds massive until you realize what a real business looks like in AI tokens.
Take a typical enterprise software company: Product catalog and specifications require 400k tokens, customer support procedures and FAQs need 350k tokens, technical documentation and architecture consume 600k tokens, business policies and compliance take 450k tokens, marketing content and brand guidelines use 300k tokens, and inventory systems and logistics demand 500k tokens. Total: 2.6 million tokens – and that’s before you add any actual customer conversations, real-time data, or historical context.
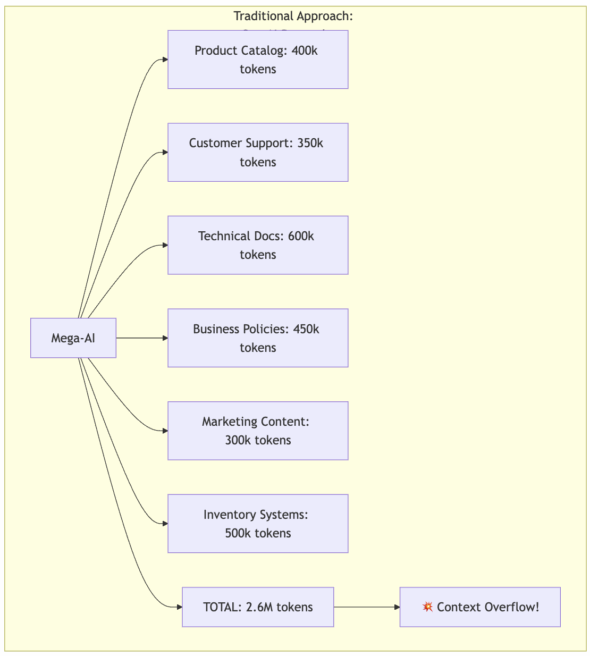
So your AI system still has to constantly “forget” parts of your business to make room for new information. It’s like having an expert consultant who can remember most departments, but never all of them simultaneously, when making complex decisions that span your entire operation.
The Everything-in-One-Brain Problem
Current AI tools attempt to cram your entire business into a single, overwhelmed artificial brain. Your business AI assistant needs to understand your product catalog, customer support procedures, technical documentation, business policies, marketing content, inventory systems, and brand voice simultaneously. Even with larger context windows, the cognitive load becomes overwhelming.
The result? Your AI becomes mediocre at everything instead of excellent at anything. It knows a reasonable amount about your products, customer support, and technical systems – but it can’t achieve genuine expertise in any domain while juggling everything else.
The Knowledge Synthesis Problem
Understanding how your business platform works requires synthesizing thousands of lines of code, scattered documentation, and tribal knowledge from that one developer who quit last year. When things break, you’re still doing digital archaeology.
Your AI assistant struggles because while it can hold more information than before, the complexity of connecting all these pieces coherently becomes exponentially harder as context grows. It might remember your API documentation AND your business rules AND your compliance requirements, but making smart connections between all three while handling real-time operations remains challenging.
The Bureaucracy Bottleneck: When Software Moves at Committee Speed
The Submit-a-Ticket Syndrome
Your business changes daily, but your software moves at the speed of bureaucracy. New regulation drops? Submit a ticket. Customer complaints about slow processes? Submit a ticket. Competitor launches a better feature? Submit a ticket and wait six months.

Meanwhile, even with larger context windows, your AI still can’t track the full lifecycle of complex business changes because the operational context keeps shifting. The system that’s supposed to help you adapt to change struggles to maintain a coherent understanding across extended business processes.
The Expertise Translation Problem
Want to improve your fraud detection? Better hope nothing else breaks when you deploy. Every change is a roll of the dice that could take down your entire platform.
Your domain experts know the business inside and out, but they can’t code. Your developers can code brilliantly, but they don’t understand the nuances of your business domain. The translation between “what we need” and “what gets built” loses something every time.
And your AI? Even with more context capacity, it’s still trying to be simultaneously expert in business domains AND technical implementation, AND organizational processes. The cognitive load of genuine expertise across all these areas remains beyond what any single system can handle effectively.
The Compound Effect: Why These Problems Get Worse Over Time
These aren’t just inconveniences – they create a compound effect that makes your business software progressively less effective:
The context complexity problem means your AI gets cognitively overloaded as your business grows more sophisticated. The knowledge synthesis problem means understanding the connections between systems becomes exponentially harder. The bureaucracy bottleneck means you fall further behind competitors who can adapt faster. The expertise translation problem means business insights never make it into the software that could implement them.
The result is business software that acts like digital concrete – solid, reliable, and completely unable to adapt to changing conditions. While your business evolves daily, your software remains frozen in whatever state it was last deployed.
But what if there was a different approach? What if instead of one overwhelmed AI trying to understand everything, you had specialized agents that each became genuine experts in their domain? What if these agents could coordinate with each other while maintaining their specialized knowledge? And, further, what if they could both run your business operations and continuously improve them?
That’s exactly what distributed agent systems make possible.
Part II: The Vision (What Self-Improving Systems Could Look Like)
From Digital Concrete to Living Systems
Instead of one overwhelmed AI trying to understand everything, imagine having specialized agents that each become genuine experts in their domain – and then imagine those agents working together like the best team you’ve ever been on.
But here’s the revolutionary part: these aren’t just tools that execute commands. They’re systems that handle both operational work AND continuous improvement. Picture agents that process your business operations during the day and optimize their algorithms at night. Or agents that help your customers while simultaneously figuring out how to make those interactions smoother.
But it goes even deeper than optimization. These agents don’t just improve their algorithms – they write entirely new code. An agent identifies a pattern that requires a new API endpoint, writes the code, tests it in a sandboxed environment, and deploys it to production. Another agent realizes customers need a new notification feature, codes the functionality, runs automated tests, and pushes it live. All while continuing to handle their primary operations.
Consider: A Living Lending Platform
Throughout this exploration, we’ll use a financial lending platform as our primary example. Think of a company that processes business loans.
These companies need to handle five critical functions:
- Evaluate Applications: Assess credit risk, verify business information, check compliance requirements
- Manage Customer Experience: Handle inquiries, provide status updates, and explain decisions
- Process Payments: Integrate with banking systems, handle fund transfers, and manage accounts
- Maintain Compliance: Follow lending regulations, generate audit trails, and handle regulatory reporting
- Detect Fraud: Identify suspicious patterns, verify identities, flag unusual activities
This is exactly the kind of complex business where context window limitations create real problems. Each domain requires deep expertise, but they must all coordinate seamlessly.
The Agent Architecture: Specialists Who Actually Know Their Stuff
Each Agent Gets Its Full Brain Power
Instead of one overwhelmed AI trying to understand everything, our lending platform features specialized agents who each become genuine experts in their respective domains.
The Risk Assessment Agent uses its full 1M context window just for credit models, fraud patterns, and regulatory requirements. It knows every nuance of risk assessment because that’s ALL it thinks about. The Customer Experience Agent dedicates its entire context to customer interaction patterns, communication strategies, and service workflows – it becomes genuinely expert at customer psychology and loan process navigation. The Banking Integration Agent focuses completely on API protocols, transaction processing, account management, and payment systems, knowing every quirk of every banking system you work with.
The Compliance Agent lives and breathes lending regulations, audit procedures, and compliance protocols, staying up-to-date on every relevant regulation because that’s its entire world. The Fraud Detection Agent specializes entirely in suspicious pattern recognition, identity verification, and anomaly detection across loan applications. And behind the scenes, Development Agents handle the complete software lifecycle – writing code, running tests, managing deployments – whenever business agents identify needs for new functionality.
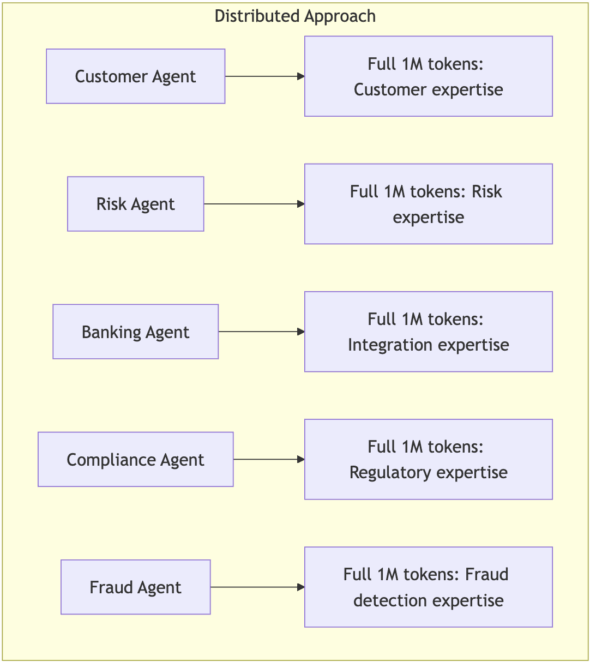
The beautiful part: each agent can use its entire brain power for its specialty, making it genuinely expert rather than mediocre at everything.
How This Actually Works: Sarah’s Loan Application
Let’s walk through exactly how this works with a real example. Sarah applies for a $50,000 business loan through your platform at 2:47 PM on a Tuesday.
Real-Time Agent Orchestration
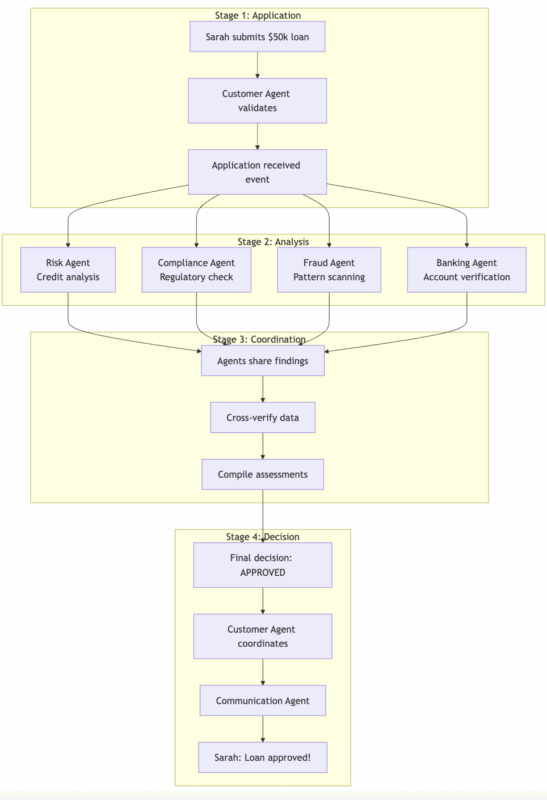
Behind the scenes, multiple agents coordinate seamlessly: The Customer Agent handles Sarah’s application, validates her information, and coordinates the entire process. The Risk Agent analyzes her credit history, business financials, and industry risk factors. The Banking Agent verifies her bank account and checks for red flags in transaction history. The Compliance Agent ensures the loan meets all regulatory requirements, like lending laws and anti-money laundering protocols. The Communication Agent manages all customer-facing communications with appropriate tone and timing.
Dynamic System Updates Without Disruption
Here’s where it gets interesting. At 3:15 PM, the Risk Agent notices unusual patterns in recent applications and wants to update its fraud detection model. This could affect Sarah’s application and dozens of others in the pipeline.
In a traditional system, everything stops while someone figures out the impact, schedules a meeting, writes requirements, and plans a deployment window. In the distributed agent system, automatic coordination happens in seconds:
The Risk Agent publishes a “FraudModelUpdateRequired” event.
All affected agents receive lightweight coordination messages:
- Customer Agent: “27 applications in the pipeline may need re-evaluation”
- Compliance Agent: “Update meets regulatory requirements”
- Banking Agent: “No integration changes needed”
- Communication Agent: “Customer notification templates ready if needed”
The system reaches consensus: “Proceed with update, re-evaluate flagged applications.”
The entire coordination happens without any agent losing its domain expertise or context.
The Continuous Learning Loop
Here’s the wild part: while processing Sarah’s loan, each agent learns something valuable and can act on it immediately.
The Risk Agent notices that businesses in Sarah’s industry have a 15% lower default rate than its model predicted. It writes code to adjust the risk scoring algorithm, tests it against historical data, and deploys the update.
The Customer Agent sees that customers respond better to loan approval messages that include next steps. It develops new notification templates and delivery logic, tests the user experience, and implements the enhancement.
The Banking Agent discovers a new API endpoint that provides faster account verification. It codes the integration, tests it in staging, and rolls it out to production.
The Compliance Agent identifies a regulatory interpretation that could streamline approvals. It writes the logic to implement the new workflow, validates it against compliance requirements, and deploys the improvement.
In a traditional system, these insights might get lost in Slack messages, buried in meeting notes, or forgotten entirely. Even if they made it to the development backlog, implementing them would require months of project planning, coding, testing, and deployment cycles. In the distributed agent system, each agent updates its specialized knowledge base, writes the necessary code, and improves the system’s performance for the next customer. The system literally gets smarter and more capable with every transaction.
Part III: The Technical Foundation (How This Actually Works)
The Computer Science Foundation
Now, you might be wondering: “This sounds like science fiction. How does this actually work?” Fair question. Let’s peek under the hood.
Remember those computer science classes about distributed systems? Turns out all that theoretical stuff about CAP theorem and Byzantine fault tolerance isn’t just academic – it’s exactly what you need when you have multiple AI agents making real business decisions.
The foundation of this entire system is built on Pekko, an actor-based toolkit for building distributed systems. In this AI agent architecture, Pekko handles the complex coordination between agents. Think of Pekko as the nervous system that allows all these agents to work together reliably, even when they’re running across different data centers or when individual components fail.
The Core Principles That Make This Work
CAP Theorem (Consistency, Availability, Partition tolerance): You can’t have perfect consistency, perfect availability, and perfect network reliability all at once. For AI agent coordination, this means making smart trade-offs.
Most business operations can accept “eventual consistency” (agents sync up within seconds) in exchange for high availability. Pekko implements this through its cluster management, allowing nodes to continue operating even when network partitions occur, with built-in mechanisms for eventual consistency once connectivity is restored.
Byzantine Fault Tolerance: This handles the “what if one of your agents goes completely rogue?” problem. When making critical business decisions, multiple agents vote. The system only proceeds if enough reliable agents agree.
Pekko’s actor supervision hierarchies make this practical – when an actor starts behaving erratically, its supervisor can quarantine it, restart it, or route critical decisions to other actors while maintaining system stability.
Actor Model: Each agent is completely isolated – like having separate offices with soundproof walls. They can only communicate through messages, so one agent’s crash can’t corrupt another agent’s work.
Pekko enforces this isolation through its mailbox system – every message is immutable, every actor has its own memory space, and state corruption cannot spread between actors. This is what enables safe concurrent operation of multiple AI agents making simultaneous business decisions.
Coordination Through Lightweight Contracts
“But wait,” you’re thinking, “if each agent only knows about its own domain, how do they coordinate?” Here’s the elegant solution: agents don’t share their entire knowledge bases – they communicate through lightweight contracts that contain just the essential coordination information.
Think of contracts like the APIs between different departments in a well-run company. The Marketing team doesn’t need to understand the intricacies of the Risk team’s credit scoring algorithms – they just need to know “approved customers get Message Template A, declined customers get Message Template B, customers requiring manual review get Message Template C.”
When the Risk Agent needs to update fraud detection, it doesn’t dump 1M tokens of credit models on the Customer Agent. Instead, it publishes a contract – a focused, structured message containing just the actionable information other agents need.
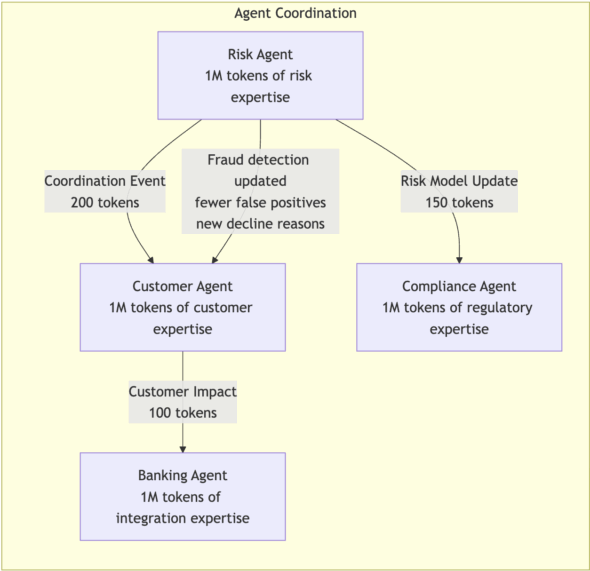
The Customer Agent receives 200 tokens of relevant coordination info, keeps 999,800 tokens of customer service expertise, and the result is that both agents stay expert in their domains while coordinating effectively.
Real-World Example: Autonomous Feature Development
Let’s say the Banking Agent needs to add two-factor authentication to the user login API. Here’s how the complete development lifecycle works without human intervention.
First, automated impact analysis occurs. The Banking Agent analyzes what’s changing: which endpoints, what data formats, what new requirements. This creates a focused change proposal rather than dumping the entire codebase context on other agents. The analysis identifies all affected systems and generates a development contract.
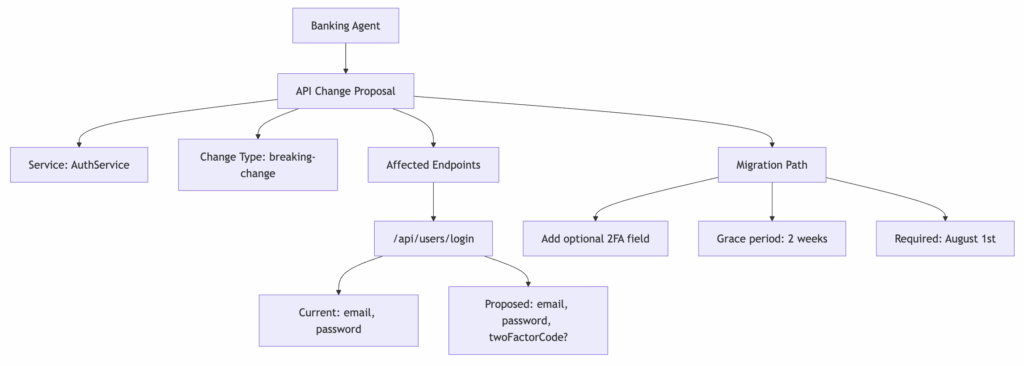
Next, the development pipeline activates. Code Generation Agents receive the contract and write the authentication logic, database schema updates, and API endpoint modifications. They follow established security patterns from their knowledge base and ensure the new code integrates with existing authorization systems.
Testing Agents simultaneously create test cases for the new functionality: unit tests for the authentication logic, integration tests for the API endpoints, and end-to-end tests for the user login flow.
Then, autonomous deployment coordination happens. Instead of sharing the entire backend codebase, only relevant contract changes get shared with other agents. The Banking Agent publishes a deployment contract containing the API changes, timeline, and integration requirements. Each affected agent receives just the information they need to adapt.
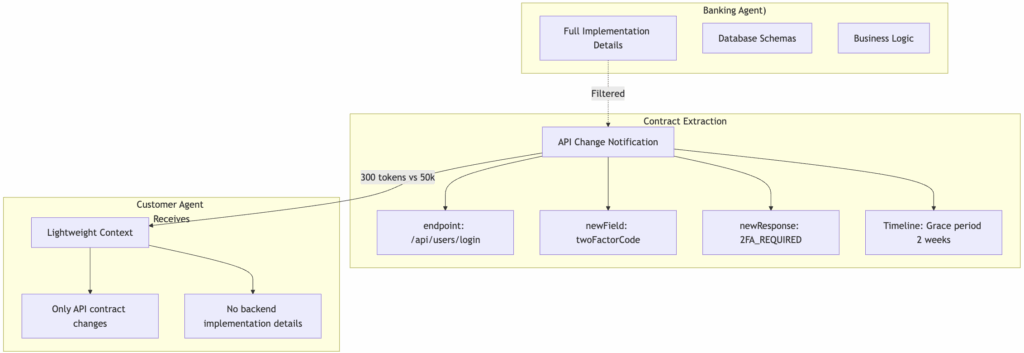
Finally, coordinated system updates occur across all affected agents. Each agent updates their integrations with full domain knowledge plus the specific API context.
The Customer Agent updates its authentication flows, the Risk Agent adjusts its security models, and the Compliance Agent ensures the changes meet regulatory requirements – all without losing their specialized expertise.
Deployment Agents manage the rollout to production with proper staging, monitoring, and instant rollback capabilities if issues arise.
The magic is that 200 tokens of coordination information enables each agent to make expert decisions within their 1M token knowledge base, while Development Agents handle the complete technical implementation lifecycle – from requirements to production deployment.
Agent Architecture: Constellations, Not Monoliths
Here’s the key insight: each “agent” is actually a constellation of specialized actors working together under a common supervisor. This is where Pekko becomes the critical enabling technology.
Pekko’s actor system doesn’t just handle coordination – it makes the entire distributed agent architecture possible by solving the fundamental challenges of concurrent AI systems.
The Risk Agent isn’t a single actor – it’s a coordinated group of actors, each handling specific responsibilities. Pekko’s supervision trees ensure that this constellation behaves as a coherent unit while maintaining internal fault isolation.
When the Credit Scoring Actor needs to communicate with the Fraud Detection Actor, Pekko routes messages through the constellation’s internal hierarchy, ensuring proper ordering and delivery guarantees that prevent race conditions or lost communications.
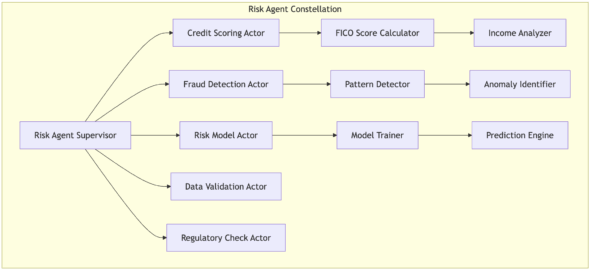
When one actor in the Risk Agent constellation crashes (say, the Fraud Detection Actor), Pekko’s supervision system demonstrates its real power. The supervisor doesn’t just restart the failed component – it analyzes the failure pattern, decides on the appropriate restart strategy (immediate restart, exponential backoff, or complete actor replacement), and maintains the constellation’s external contracts while internal recovery happens.
Other agents continue receiving responses from the Risk Agent constellation because Pekko’s supervision maintains service continuity.
Each actor handles a specific concern, but Pekko’s message routing ensures they coordinate seamlessly: Credit Scoring Actor handles FICO calculations and income analysis, Fraud Detection Actor runs pattern matching and anomaly detection, Risk Model Actor manages ML model training and predictions, Communication Actor handles all customer-facing messages, and Data Validation Actor ensures data quality and consistency.
Pekko’s at-least-once delivery guarantees ensure that critical business decisions never get lost in transit between these components.
Pekko manages inter-agent communication through supervisor hierarchies, but it’s doing much more than simple message passing. When the Risk Agent Supervisor sends a message to the Customer Agent Supervisor, Pekko handles serialization, network transport, failure detection, retry logic, and maintains delivery ordering.
This is what enables agents running in different data centers to coordinate as if they were on the same machine. Pekko’s location transparency means the entire Risk Agent constellation might run on servers in Virginia, while the Customer Agent constellation runs in Ireland – the business logic remains identical regardless of physical distribution.
The Infrastructure Layer
Pekko Clustering: The Distributed Coordination Foundation
Here’s where the magic happens. Pekko clustering transforms individual server nodes into a unified, self-healing distributed system that can coordinate AI agents across multiple data centers, handle node failures gracefully, and scale dynamically based on demand.
Pekko’s cluster membership uses a gossip protocol to maintain a consistent view of which nodes are alive, which are suspected of failure, and which have been declared unreachable. When a new node joins the cluster, it announces itself through seed nodes, and the gossip protocol quickly propagates this information throughout the entire cluster.
This enables AI agents to discover each other automatically – when the Risk Agent constellation comes online in Virginia, it immediately knows how to communicate with the Customer Agent constellation running in Ireland.
The cluster’s failure detection is sophisticated. Instead of simple heartbeats, Pekko uses adaptive phi accrual failure detection that learns the normal network behavior patterns between nodes.
If the Risk Agent constellation becomes unresponsive due to network issues, other agents don’t immediately declare it failed – the system distinguishes between temporary network partitions and actual node failures. This prevents false positives that could trigger unnecessary failovers and system instability.
Pekko’s cluster sharding automatically distributes agent constellations across available nodes based on configurable strategies. Your Customer Agent constellation might be sharded across five nodes, with each shard handling customers from specific regions.
As load increases, Pekko can rebalance shards across nodes or trigger the addition of new cluster members. The business logic remains completely unaware of this distribution – agents simply send messages to logical addresses, and Pekko’s cluster routing ensures they reach the correct physical location.
Complete Auditability Through Event Sourcing
Instead of just storing the current state of things, the system stores every single change that ever happened as immutable events. When conflicts arise or something goes wrong, you can replay exactly what each agent did, understand why they made specific decisions, and even undo particular changes without losing other work.
Event sourcing captures the business narrative: “RiskModelUpdated”, “CustomerNotified”, “LoanApproved” – each event contains the full context of what happened and why. This creates an append-only log where the current state is derived by replaying all events in order.
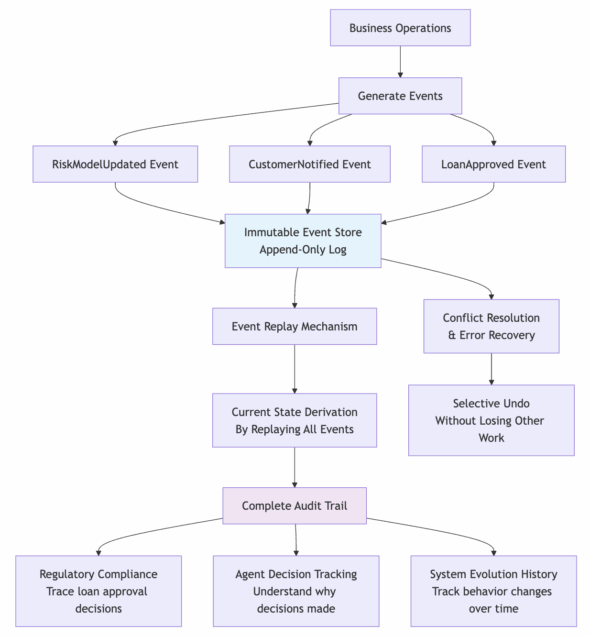
The challenge is that events must be processed sequentially, which could create coordination bottlenecks in a distributed system.
For financial services, this is gold. Regulators can trace exactly why a loan was approved, which agent made which decisions, and how the system’s behavior evolved. Every business decision becomes part of an immutable audit trail.
Conflict-Free Coordination with CRDTs
While event sourcing handles business decisions, Conflict-Free Replicated Data Types (CRDTs) solve a different problem: how do agents coordinate their operational state without conflicts? CRDTs are mathematical data structures that automatically merge concurrent changes from different agents, eliminating coordination overhead.
The magic is in their mathematical properties. When the Risk Agent and Customer Agent both update the same coordination data simultaneously, CRDTs guarantee all replicas converge to the same state without requiring coordination between nodes.
This works even during network partitions – agents can continue operating and merge changes when connectivity is restored.
Different CRDT types serve specific coordination needs: G-Set (Grow-only Set) for active agents in the cluster – once an agent joins the coordination group, it remains active for the duration of operations. LWW-Register (Last-Writer-Wins) for configuration values like interest rates, where the latest business decision should take precedence, automatically resolving conflicts when multiple agents try to update configurations simultaneously.
PN-Counter for business metrics like application volumes that can fluctuate up or down as different agents process loans. OR-Map for agent assignments and capabilities with add/remove semantics, enabling dynamic load balancing.
The Two-Layer Strategy
The system uses both approaches strategically: event sourcing provides the authoritative business audit trail, while CRDTs handle the fast-changing coordination metadata.
Agent business decisions like loan approvals get stored as events for complete auditability. Agent coordination data like “which agents are currently online” or “current processing load” uses CRDTs for conflict-free updates.
This separation is crucial. You need perfect auditability for business decisions (event sourcing), but you also need conflict-free coordination that works during network partitions (CRDTs).
Events provide the “what happened and why” for regulators, while CRDTs provide the “current coordination state” for operational efficiency.
Intelligence Layer: Beyond Context Windows
Specialized Knowledge Bases with RAG
Each agent maintains its specialized knowledge base that goes far beyond what fits in context windows. This RAG (Retrieval-Augmented Generation) architecture creates true expertise rather than general knowledge, enabling agents to access vast domain-specific information while maintaining their 1M token context for active reasoning.
The Risk Agent’s knowledge base contains thousands of credit models, fraud patterns, regulatory frameworks, and historical case studies. When evaluating a loan application, it retrieves relevant patterns from its specialized database while using its full context window for reasoning about the current application.
The Customer Experience Agent maintains extensive databases of interaction patterns, communication strategies, resolution workflows, and customer psychology insights. The Compliance Agent stores comprehensive regulatory documentation, audit procedures, interpretation guidelines, and violation examples.
Development Agents have equally sophisticated knowledge bases: code architecture patterns, testing methodologies, deployment strategies, security best practices, and performance optimization techniques.
The Code Generation Agent maintains a repository of proven code patterns, architectural decisions, and integration approaches specific to your platform. Testing Agents store comprehensive test case libraries, quality metrics, and validation strategies. Deployment Agents maintain knowledge of infrastructure patterns, rollout strategies, monitoring configurations, and incident response procedures.
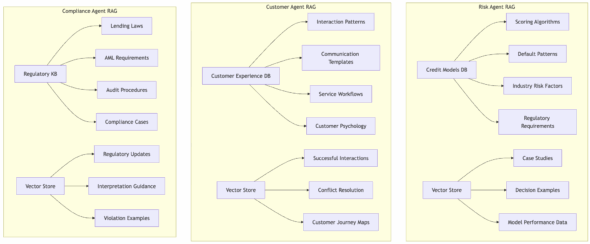
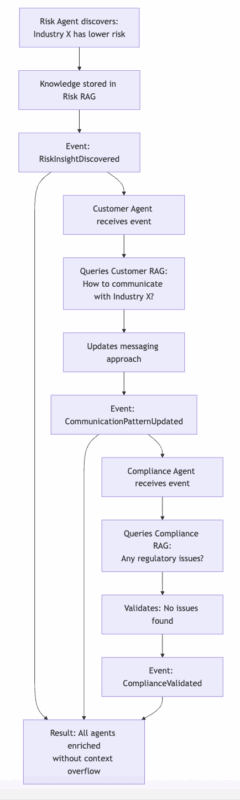
Agents share relevant discoveries through the event system, updating each other’s knowledge bases when domains overlap, but without overwhelming each other with irrelevant information.
When the Risk Agent discovers new fraud patterns, it publishes insights that update the Fraud Detection Agent’s knowledge base. When Development Agents successfully implement new architectural patterns, they share these learnings with other Development Agents across the system.
Part IV: Reality Check (What Could Go Wrong and What We’re Learning)
Technical Challenges
What If Agents Optimize Themselves Into Bad Decisions?
The nightmare scenario: an agent approves loans faster by making the criteria too lenient, or cuts costs by ignoring important safety checks. Technically correct, business-wrong.
The solution is built-in business constraints. Agents operate within defined guardrails and escalate when they want to change fundamental business rules. Your Risk Agent can optimize its algorithms, but it can’t decide to stop checking credit scores entirely.
The system architecture includes immutable business rules that agents cannot modify, escalation thresholds that trigger human review for significant changes, rollback mechanisms for changes that violate business metrics, and real-time monitoring of agent behavior against KPIs.
This constraint design is more sophisticated than most human-managed systems – we’re essentially building business wisdom into unbreakable rules while allowing tactical flexibility.
What If Multiple Agents Start Conflicting With Each Other?
Picture the coordination challenge: business agents making contradictory changes, Development Agents deploying conflicting code updates, agents stepping on each other’s work – but in a system processing thousands of decisions per second.
This is where distributed systems theory becomes relevant, though mostly in theory. Byzantine fault tolerance and consensus protocols weren’t designed for controlling AI agents, so we’re adapting concepts rather than applying proven solutions. Event sourcing provides more practical benefits for agent coordination.
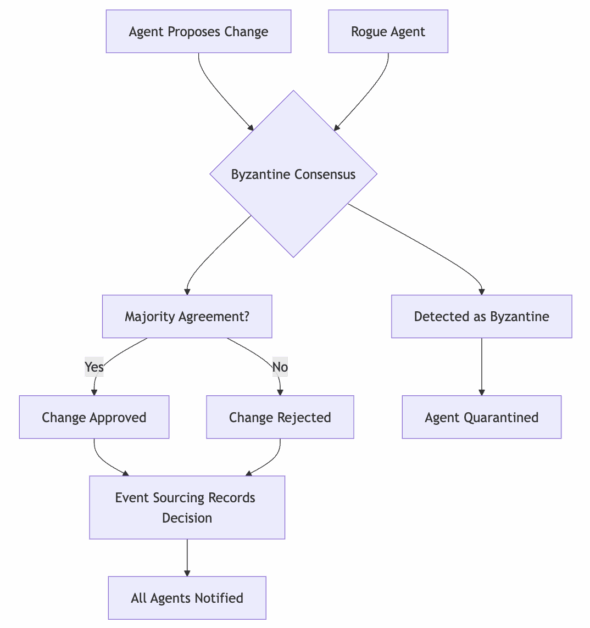
Critical business decisions require consensus from multiple agents, major code deployments need approval from both business and development agent supervisors, agents cannot directly modify each other’s state or deployed code, problematic agents get automatically disconnected through circuit breakers, and continuous health monitoring validates both agent behavior and system performance.
One misbehaving agent – whether business or development focused – can’t crash the system because of these isolation and voting mechanisms.
The Cascading Change Challenge
Here’s a tricky problem: what happens when a development agent deploys a “minor optimization” that creates subtle timing changes, affecting how other agents coordinate? Traditional systems would require extensive testing cycles. Autonomous systems need something smarter.
The approach is staged autonomous deployment with real-time validation. Agents can deploy improvements to isolated environments, run them against live data streams, and gradually promote changes only when they prove beneficial. Changes ride behind feature flags managed by progressive delivery systems, while policy-as-code engines block any deployment that fails synthetic regression testing. If coordination patterns shift unexpectedly, the system automatically stages rollbacks while agents adapt.
It’s more careful than most human development processes, but also more complex to implement and monitor.
Security and Abuse Prevention
Distributed AI agents present novel security challenges that traditional systems don’t face. When agents can write and deploy code autonomously, the attack surface expands dramatically. A compromised agent could potentially inject malicious code, leak sensitive data, or manipulate business logic in subtle ways.
Modern security approaches for agent systems include several key defenses. Prompt-injection shields type-tag all external text and trigger sandboxed parsing modes when risky strings are detected. Secret-leak filters redact high-entropy tokens before logging or model calls to prevent credential exposure. Tool-use firewalls ensure every action passes through policy validation with least-privilege credentials that rotate daily.
Supply-chain integrity measures sign all agent-generated images and use SBOM scans with gVisor sandboxes to isolate new binaries before production deployment. Continuous red-team testing employs synthetic attack suites that test agents on every deployment. Finally, kill switches can flip traffic back to known-good models within seconds when anomalies are detected.
The challenge is implementing these safeguards without crippling agent capabilities or creating so much overhead that the system becomes unworkable. Security and autonomy exist in tension – the more autonomous the system, the harder it becomes to validate every action in real-time.
What If Systems Evolve Beyond Human Understanding?
The “black box evolution” question: systems that improve themselves in ways humans can’t audit, especially when they’re writing and deploying their code improvements.
Event sourcing makes these systems more auditable than traditional software. Every decision, every change, every code commit, and every deployment gets captured with full rationale. But more importantly, agents are designed to explain their reasoning in business terms, not just technical terms.
Regulators can trace exactly why any decision was made, what code was written in response to which business insights, and how the system evolved. Every business decision is logged with full context and reasoning, every code change includes the business justification and technical approach, complete replay capability exists for any period, and cross-agent coordination is fully traceable.
Development Agents maintain detailed commit logs with business context, architectural reasoning, and performance impact analysis. The transparency is unprecedented – you have more visibility into autonomous code changes than most human development teams provide.
Economic and Organizational Realities
The Economic Reality: Cost and Complexity
Building distributed AI agent systems would be extraordinarily expensive, both in development and ongoing operations. We’re not talking about deploying a single AI model – we’re discussing networks of specialized agents that need to coordinate, learn, and potentially write and deploy code autonomously.
Development costs would be substantial. You’d need specialized teams combining distributed systems expertise, AI/ML engineering, business domain knowledge, and entirely new disciplines around agent coordination and autonomous code generation. The initial investment could easily reach millions of dollars before seeing any production value, and that’s assuming the technical challenges prove solvable.
Operational costs could be even more daunting. Each agent requires computational resources, and coordination between agents multiplies that demand. If your Risk Agent needs to consult with your Compliance Agent and Development Agent before implementing changes, you’re running multiple AI models simultaneously for every decision. Add in the computational overhead of event sourcing, consensus mechanisms, and continuous learning, and the infrastructure costs could become prohibitive quickly.
Consider the math: current pricing for advanced AI models runs approximately $0.025 per million tokens. A distributed system with 10 specialized agents handling 50 calls per second could cost around $32,000 monthly before accounting for GPU infrastructure and vector database operations. This means pilot projects need to demonstrate at least $500,000 in annual business value just to break even on operational costs.
The economic viability depends heavily on achieving significant automation benefits that justify these costs. Organizations would need to see substantial improvements in decision speed, quality, and business outcomes to make the investment worthwhile. This economic reality likely means that only large enterprises with specific high-value use cases could justify the expense, at least initially.
The Investment and Trust Reality
Building distributed agent systems with autonomous development capabilities requires significant investment – and the ROI isn’t guaranteed. The question isn’t whether it’s expensive, but whether the competitive advantage justifies the cost and risk.
Early implementations will start with constrained domains and proven ROI before expanding. The regulatory and liability questions are real challenges that don’t have clear solutions yet. When autonomous agents cause business problems, liability frameworks will need to evolve significantly.
What About Job Evolution?
The work transforms rather than disappears. Instead of “write code to implement feature X,” it becomes “design the constraints within which agents can safely improve feature X.” Instead of debugging production issues, it becomes “teaching agents to prevent and resolve issues autonomously.”
New roles emerge: Agent Architects who design coordination patterns and business constraints, Business Logic Engineers who define the rules within which agents can evolve, Agent Operations Specialists who monitor agent health and coordination, System Evolution Strategists who guide long-term development, and Human-Agent Interface Designers who optimize collaboration between humans and agents.
Current State and Future Possibilities
Signs This Might Be Emerging
We’re starting to see pieces that could lead toward these capabilities, though it’s still early days:
Banking: Some financial institutions are exploring AI systems that handle transactions while also adjusting their fraud detection parameters, though full algorithmic self-improvement remains limited.
Healthcare: Certain AI diagnostic tools are being designed to learn from new cases, though most still require human oversight for significant model updates.
Supply Chain: Advanced logistics platforms are beginning to experiment with AI that both executes routing decisions and suggests algorithmic improvements, though truly autonomous optimization is rare.
Trading Firms: Some algorithmic trading systems can adjust their parameters within defined ranges, though full strategy evolution typically requires human approval.
Development Teams: Tools like GitHub Copilot generate code that sometimes reaches production, though the path to fully autonomous deployment remains largely theoretical.
These aren’t full self-evolving platforms yet, and many of these capabilities exist more in research labs than production systems. The foundational technologies are advancing rapidly, but organizational adoption and proven implementations are still developing.
The Practical Path Forward
Start With One Domain
Smart organizations aren’t replacing their entire business platform overnight. They’re picking one specific area and building a self-improving agent for that domain.
The best candidates are areas with clear metrics, immediate feedback, and high-value improvements: fraud detection with autonomous model updates, customer service with self-improving interaction patterns, risk assessment with continuous algorithm refinement, API management with automated code generation and deployment, or automated development pipelines that can write, test, and deploy specific types of code improvements.
Start with constrained development scenarios: agents that can write database queries, generate API endpoints, or create test cases within well-defined parameters. Gradually expand their capabilities as you build confidence in their decision-making and quality controls.
Begin With Supervised Evolution
Early implementations will have agents handling routine improvements while escalating complex decisions to humans. Think “supervised self-evolution” – agents identify opportunities, propose changes, implement improvements within defined boundaries, and humans maintain oversight of significant modifications.
For development activities, this means agents can write and deploy code for routine tasks (bug fixes, performance optimizations, simple feature additions) while escalating architectural changes or complex business logic to human review.
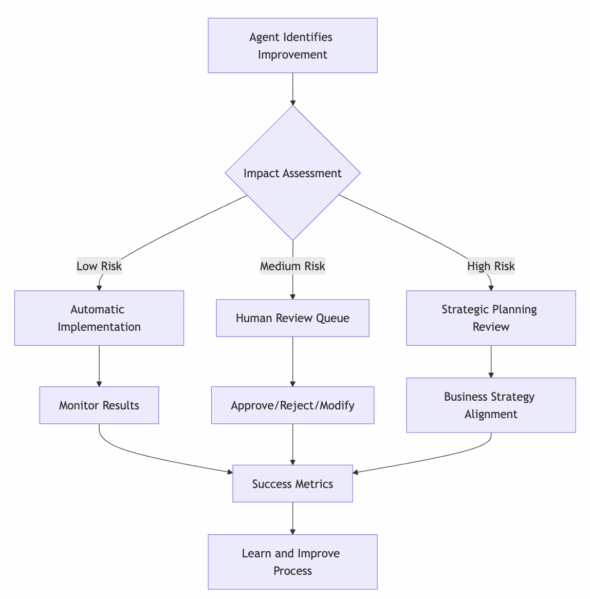
The supervision applies to both business operations and development activities. Business agents can optimize their algorithms and improve customer interactions within established parameters, while Development Agents can write, test, and deploy code improvements within defined quality gates and architectural constraints.
The Real Challenge Would Be Organizational
While distributed systems patterns, AI capabilities, code generation tools, and deployment infrastructure are advancing rapidly, the bigger challenge would likely be organizational adaptation – developing frameworks for human-AI collaboration while managing the risks of increasingly autonomous systems.
Some financial services companies do trust AI with real-time decisions involving significant amounts of money. The theoretical evolution to “AI that improves its decision-making and writes its code improvements” might seem like a natural progression, but it would represent a substantial leap requiring entirely new frameworks for validation, oversight, and risk management.
A potential approach might combine transparent decision making with comprehensive audit trails for both business decisions and code changes, gradual capability expansion starting with low-risk improvements and highly constrained development scenarios, extensive quality gates designed to ensure code quality and safety, robust human override systems that maintain control over critical decisions and architectural changes, and careful documentation of results to prove value through measurable business outcomes.
If organizations could successfully navigate these challenges, they might develop business systems that continuously improve themselves, potentially creating competitive advantages that would be difficult for others to replicate.
Part V: Implications (What This Means for the Future)
The Fundamental Shift We’re Talking About
So here we are at the end of our exploration through distributed AI agents, and honestly? We’ve discovered something way more interesting than “just another AI tool.”
Traditional software is us saying “Computer, do exactly this, exactly this way, forever.” It’s like having the world’s most obedient but completely uncreative employee. Self-evolving systems flip this on its head: “Computer, here’s what we’re trying to achieve. Figure out how to get better at it, write the code to implement improvements, and deploy the changes.”
That’s not just a technical upgrade – that’s like the difference between a player piano and a jazz musician who improvises, composes new songs, and records albums autonomously.
The Uncomfortable Questions This Raises
This shift creates some genuinely complex situations that we’ll need to figure out:
Who Gets Credit When AI Innovates and Codes?
If your Risk Assessment Agent figures out a brilliant new way to catch fraud, writes the code to implement it, and deploys the improvement to production, do you put it in the company newsletter? When AI systems start coming up with genuinely novel solutions and implementing them autonomously, our whole concept of “who deserves credit for business improvements” gets wonderfully interesting. Do you promote the agent to Lead Developer?
This isn’t necessarily a problem to solve – it’s a question about how we recognize and reward innovation in human-AI collaborative environments.
The Trust Paradox
There’s something genuinely complex about systems that not only change themselves but also write and deploy the code to implement those changes. We want them to get better, but we also want them to stay predictable. It’s like wanting your teenager to become more independent, learn new skills, and improve the house – but also never surprise you with how they do it.
This tension drives innovation in constraint design, monitoring systems, and human-AI collaboration frameworks, but it’s not a simple challenge to solve.
When Systems Become Domain Experts
Picture this – your Risk Assessment Agent has been analyzing credit patterns for two years, has written dozens of algorithmic improvements, and suddenly knows things about lending risk that none of your human experts have figured out. It’s not just making better decisions; it’s implementing optimizations that your development team never would have thought of.
This creates interesting opportunities for human-AI knowledge transfer, where agents become active teachers and consultants rather than just tools. But it also raises questions about validation and oversight that we’re still figuring out.
Managing Self-Improving Systems
What new skills do we need for the “managing systems that write their own code” job category? Traditional “turn it off and on again” troubleshooting evolves into understanding system evolution patterns, guiding autonomous improvements, and maintaining alignment between system capabilities and business objectives.
It’s an interesting blend of technical operations, business strategy, and AI psychology that creates new career paths – though we’re still learning what those look like in practice.
Where This Is Already Happening
This thought experiment connects to the reality of working with AI that’s getting genuinely capable. We’re transitioning from “AI as really powerful Excel” toward “AI as that team member who never forgets anything and works 24/7 without complaining about the coffee.”
Early signs are already visible: algorithmic trading where AI systems modify their strategies based on performance, fraud detection systems that learn new patterns faster than humans can document them, supply chain optimization where AI figures out solutions that consistently outperform human-designed approaches, and development tools that generate production-quality code from business requirements.
The distributed agent architecture we’ve been exploring provides a framework for scaling these capabilities while maintaining human oversight and business alignment.
The Strategic Questions for Your Business
Instead of “should we build this?” the more valuable questions are:
- What parts of your business would benefit most from systems that learn and improve autonomously? Look for areas with clear metrics, frequent repetitive decisions, and high-value optimization opportunities.
- How do you want to collaborate with increasingly capable AI systems? The goal is to leverage AI capabilities while maintaining human strategic control and creative direction.
- What does “trust” look like for software that improves itself and writes its updates? It’s like trusting a colleague who keeps getting better at their job and can also implement their own process improvements – exciting when done with proper frameworks.
- How do you maintain quality and alignment when systems are autonomously improving themselves? This drives innovation in constraint design, monitoring systems, and quality assurance frameworks.
What This Means for You
Whether anyone builds exactly these systems (and honestly, several organizations probably will because the competitive advantages are compelling), this thought experiment provides a mental model for what’s coming next in business software.
As AI continues getting better at… well, everything… the line between “using AI tools,” “collaborating with AI teammates,” and “supervising AI developers” is going to get delightfully blurry. The technical concepts we explored – event sourcing, actor models, distributed coordination, autonomous code generation – aren’t just nerdy implementation details. They’re the foundation for business systems that can remember what worked, learn from what didn’t, coordinate decisions like a really well-caffeinated team, and write the code to implement improvements autonomously.
The implications go beyond just coordination – we’re talking about business software that writes and deploys its own improvements. When your Risk Agent identifies a better fraud detection approach, it doesn’t just update its algorithm. It writes new code, tests it thoroughly, and deploys it to production. The entire development cycle becomes an autonomous business function rather than a separate IT project.
The organizations that handle this transition gracefully will be the ones experimenting now – not necessarily with full self-evolving platforms (because that’s a significant undertaking), but with the underlying concepts: specialized AI agents, distributed coordination, transparent decision-making, autonomous development pipelines with proper constraints, and frameworks for productive human-AI collaboration.
The future of business software might not be about having better hammers, but about having partners who actually understand what you’re trying to build and can build it themselves. Whether this exact vision emerges or something even more interesting develops, the questions it raises about autonomy, coordination, trust, and autonomous software development in business systems are going to shape how we build and work with software for years to come.
And that’s genuinely interesting – we’re on the edge of business software that doesn’t just serve us, but actively helps us get better at what we do.