
This Snake project is a useful way to study how a simple game-playing agent works end-to-end. It is small enough to read quickly, but complete enough to show the important parts: state representation, neural network inference, scoring, and iteration through training.
Read on to learn:
- Why Snake works well as an AI learning exercise
- How the same game engine supports both training and browser play
- What information the 30-input neural net receives
- How neuroevolution improves the model over time
- How to trace a single decision from board state to chosen move
Why Snake Is a Good Learning Project
Snake is simple, but it still creates meaningful decision-making problems. Early in a game, many moves are safe. Later, the board becomes more constrained as the snake grows and available paths shrink. That forces the agent to balance short-term rewards with longer-term survival.
That makes Snake a good environment for learning how an agent works. The rules are easy to understand, the feedback is immediate, and the full decision loop is short enough to inspect without a lot of supporting infrastructure.
It also makes Snake a good code-reading exercise. If you are trying to understand an unfamiliar project, this kind of setup gives you a clear path: identify the inputs, inspect the decision function, look at how performance is scored, and then follow the training loop.
The Shape of the App
The current version of the project separates the game logic from the presentation layer. The browser UI acts as a thin adapter over the same core engine used during evaluation and training.
That structure matters because it keeps the decision-making code in one place. Once the rules and state transitions live in a shared core, you can inspect behavior in the browser and run large batches of training games without maintaining two different implementations.
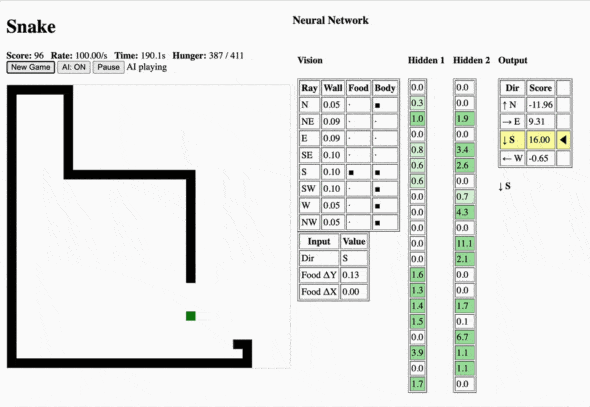
Step 1: Understand What the Network Sees
The model takes 30 inputs. The first 24 come from eight rays cast outward from the snake’s head. For each ray, the engine records three values:
- Distance to the wall
- Whether food appears along that ray
- Whether the snake’s body appears along that ray
After that, the engine adds four one-hot direction flags and two normalized values that describe the food’s offset from the snake’s head.
GameCore.prototype.getVision = function() {
var head = this.snake[0];
var inputs = [];
for (var r = 0; r < RAY_DIRECTIONS.length; r++) {
var ray = RAY_DIRECTIONS[r];
var distance = 0;
var foodFound = 0;
var bodyFound = 0;
var y = head.y;
var x = head.x;
while (true) {
y += ray.dy;
x += ray.dx;
distance++;
if (y < 0 || y >= this.height || x < 0 || x >= this.width) break;
if (this.board[y][x] === FOOD && !foodFound) foodFound = 1;
if (this.board[y][x] === SNAKE && !bodyFound) bodyFound = 1;
}
inputs.push(1 / distance);
inputs.push(foodFound);
inputs.push(bodyFound);
}
inputs.push(this.direction === DIRECTION_NORTH ? 1 : 0);
inputs.push(this.direction === DIRECTION_EAST ? 1 : 0);
inputs.push(this.direction === DIRECTION_SOUTH ? 1 : 0);
inputs.push(this.direction === DIRECTION_WEST ? 1 : 0);
inputs.push((this.food.y - head.y) / this.height);
inputs.push((this.food.x - head.x) / this.width);
return inputs;
};In practice, this input vector gives the agent two kinds of information: local obstacle awareness and a rough sense of where the food is. That is enough to support useful behavior without making the state representation hard to follow.
Step 2: Understand the Network Structure
The model shape is [30, 20, 20, 4]. That means:
- 30 input values
- Two hidden layers with 20 neurons each
- 4 output values, one for each direction
The network uses ReLU activations in the hidden layers and a linear output layer. At inference time, the chosen move is simply the direction associated with the largest output value.
NeuralNet.prototype.forward = function(inputs) {
var activation = inputs;
this.lastActivations = [inputs];
for (var i = 0; i < this.weights.length; i++) {
var w = this.weights[i];
var b = this.biases[i];
var isOutput = (i === this.weights.length - 1);
var next = [];
for (var j = 0; j < w.length; j++) {
var sum = b[j];
for (var k = 0; k < activation.length; k++) {
sum += w[j][k] * activation[k];
}
next.push(isOutput ? sum : Math.max(0, sum));
}
activation = next;
this.lastActivations.push(activation);
}
return activation;
};This network has (30*20 + 20) + (20*20 + 20) + (20*4 + 4) = 1124 total parameters. That is small enough to reason about directly, which is part of what makes the project useful for learning.
Step 3: Understand How Training Is Scored
Training uses neuroevolution rather than backpropagation. A population of networks plays the game, each network receives a fitness score, and the stronger performers are used to produce the next generation through selection and mutation.
The key idea is not the specific evolutionary method. The key idea is the evaluation loop: run many games, score each result, keep the better policies, and repeat.
GeneticAlgorithm.prototype.fitness = function(score, steps) {
return score * score * 5000 + steps;
};This fitness function makes food collection much more important than simply surviving for extra steps. Squaring the score heavily rewards agents that actually eat. The + steps term still helps separate weak policies early on, when many networks fail to score at all.
Step 4: Trace One Decision End to End
If you want to understand the project quickly, trace a single move. The core decision loop is short:
- Read the board into a fixed input vector.
- Run the input vector through the neural net.
- Pick the direction with the highest output score.
function decide(game) {
var vision = game.getVision();
var outputs = this.net.forward(vision);
var bestIdx = 0;
for (var i = 1; i < outputs.length; i++) {
if (outputs[i] > outputs[bestIdx]) bestIdx = i;
}
return DIRECTIONS[bestIdx];
}That path from state to action is the most useful part of the system to study. The board becomes numbers, the network scores the possible moves, and the highest score becomes the action. Once that flow is clear, the rest of the project is much easier to follow.
What This Teaches Beyond Snake
The broader lesson is that small projects become much easier to understand when you can evaluate them systematically. Instead of treating the code as a black box, define the inputs, define the outputs, make intermediate state visible, and run the same loop many times.
That approach transfers well to older codebases, too. If you can expose state, score outcomes, and inspect decisions, you can usually understand behavior faster and make changes with more confidence.
Snake is just a compact example of that process. It gives you a manageable system where you can study representation, inference, evaluation, and iteration without much overhead.
Source:
github.com/papes1ns/snake