Article summary
Our team recently finished designing an explainer to help users understand certain PDF documents they may view. To connect the notes to the PDF, we needed to annotate the PDFs themselves.
Generally, PDF-JS (or pdfjs-dist) is a great library to use for manipulating PDFs. However, our team needed to perform the manipulation server-side and didn’t have the browser libraries needed by PDF-JS.
As it turned out, a combination of libraries makes it easy to draw on and annotate PDFs server-side. Here are several tools that were useful for me.
Parsing and Extracting
What – This tool allowed us to parse the PDF’s text content, including coordinates and color data for the text as well.
How – To annotate the right page within the PDF document, we needed to find the correct page numbers for extraction. This meant parsing all the texts in the package and saving them to a preferred structure for searching. In this case, the preferred structure was an array, pdfResult, with each page content as an object element, pageContent.
type pdfResult = pageContent[];
type pageContent = {
page: number;
textContent: string;
};
const parsePdf = (file) => {
return new Promise((resolve, reject) => {
const result: pdfResult = [];
let textString: String = "";
new pdfreader.PdfReader().parseFileItems(file, function (err, item) {
if (err) {
console.log(err);
reject(err);
}
// landing on a new page, add preview text to the page object then clear
if (item && item.page !== undefined) {
const page = {
page: item.page as number,
textContent: textString.replace(/ /g, ""),
};
result.push(page);
textString = "";
}
// add text to page array
if (item && item.text) {
textString += item.text;
}
if (!item) {
resolve(result);
console.log("--successfully parsed pdf: ", file);
}
});
});
};
What – This tool allowed us to create, extract, and modify (draw text, boxes, etc.) PDFs.
How – In this sample code, given that I parsed the PDF and found the pages I needed, I was able to load the original package and create a new package. Then I copied the three necessary pages I needed into the new PDF and, finally, saved the PDF to a new file.
const extractPages = async (pageNumbers) => {
const pdfPackage = await PDFDocument.load(fs.readFileSync(filePath));
const newPdf = await PDFDocument.create();
const [first, second, third] = await newPdf.copyPages(pdfPackage, pageNumbers);
newPdf.addPage(first);
newPdf.addPage(second);
newPdf.addPage(third);
const newPdfBytes = await newPdf.save();
fs.writeFileSync(disclosureFilePath, newPdfBytes);
console.log("--successfully wrote to ", disclosureFilePath);
};
Drawing and Annotating
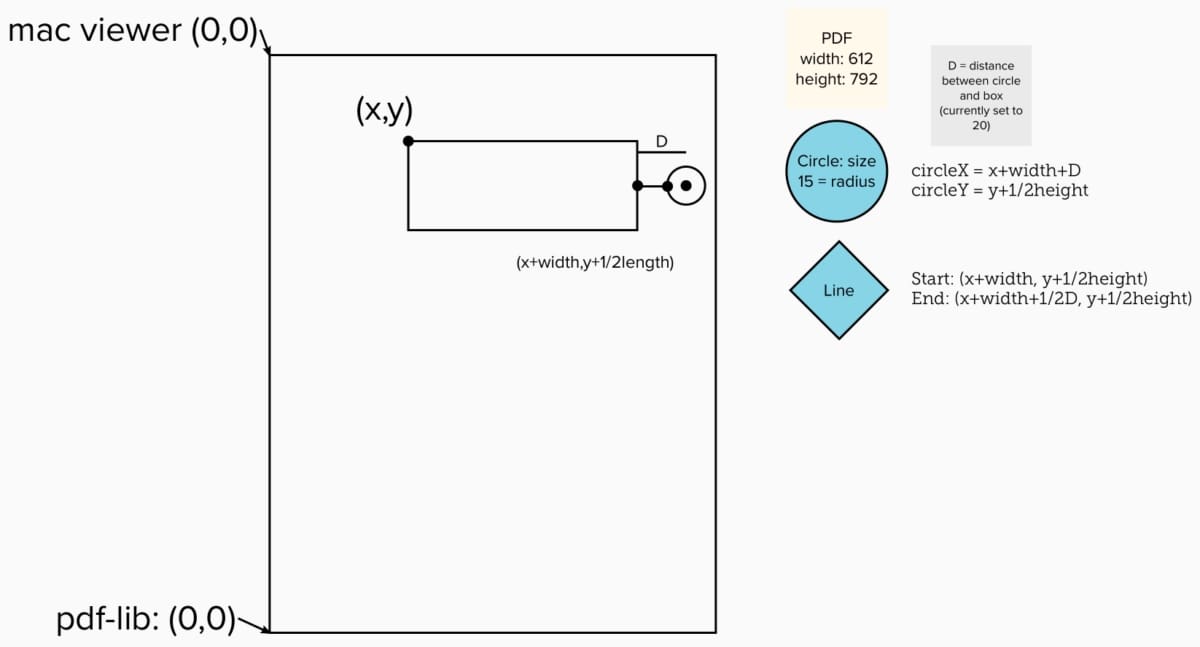
To start drawing and annotating the PDF, I used a combination of Mac’s built-in Preview and PDF-lib. The only tricky part was figuring out that the coordinates (0,0) are different between Mac’s Preview and PDF-lib, so I needed to use a little math. As I was doing these calculations, I figured out all the coordinates needed for annotating a rectangle and the related circle, line, and numbering according to the initial (x,y).
What -On PDF-lib’s site, the documentation for methods and APIs are pretty solid. “drawRectangle” is one of the many things you can use to annotate the PDF.
page.drawRectangle({
x: 25,
y: 75,
width: 250,
height: 75,
rotate: degrees(-15),
borderWidth: 5,
borderColor: grayscale(0.5),
color: rgb(0.75, 0.2, 0.2),
opacity: 0.5,
borderOpacity: 0.75,
})
What – This neat tool by Edward Hew helped me translate the hex values that our designer gave us to the percentage RGB that PDF-lib requires.
Overall, when you need to parse and annotate a PDF on the server-side, PDF-Lib with PDFReader is a great combination to substitute PDF-JS. PDFReader allowed us to parse the text and search for the pages we need, and PDF-Lib allowed us to draw all sorts of shapes and text.