Article summary
When managing a software project that has both design and development scope, I have come to prefer using an integrated backlog of tasks and separate burn charts to track design and development efforts.
Atomic continuously experiments with project management practices that help our poly-skilled teams manage their efforts and predictably deliver custom software products.
I’ve previously written about using integrated backlogs and burn charts and noted in my post that an integrated burn chart can be a bad solution if your team will have people inconsistently allocated throughout the course of the project. Inconsistent allocation can be problematic for burn charts regardless if the team member is a designer or a developer, but I’ve found through experience that it’s almost always true that the design effort on a project will have inconsistent allocation. The potential burn chart distortions resulting from inconsistent designer allocation are also likely increased due to a hours per point skew between design and development tasks.
Design Capacity Allocation
The capacity allocation graph below shows a common pattern I’ve frequently observed for small teams (the pattern is similar, with scaled hours for larger teams). As an example, let’s assume the graph represents a 32 week web development project.
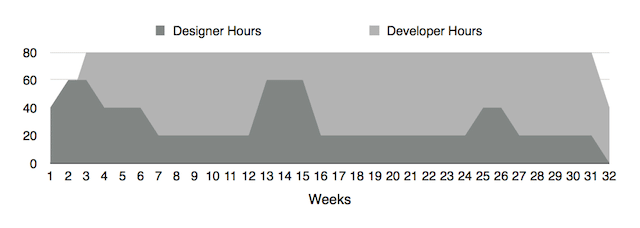
The project will generally start with a developer and designer working together for a week to kick off the Research, Design, and Planning phase of the project. Usually some extra design capacity is added at this time as the team is going through cycles of creative divergence and convergence on both conceptual and tangible aspects of the product’s design.
Implementation begins around week four, after the high-level product direction is set and the team has enough definition to focus on implementation for a few months. Developer capacity increases as development now generally becomes the bottleneck for implementation. Design capacity decreases as the design role becomes more focused on stewardship and tangible deliverables.
The design capacity peaks at weeks 12 and 25 because the team has deferred several epic stories until later in the project. At these points, more design capacity is given to the team so they can go through a mini-RDP phase while continuing to make progress on previously defined tasks.
The capacity allocation graph shows how the project plays out over time, but let’s see how two common burn chart pitfalls play out during the project.
Pitfall #1 – Inconsistent Allocation
By week four, let’s assume the team had a backlog of design and development tasks decomposed and estimated in points totaling 1,530 (390 design points and 1,140 development points). To keep the math simple, let’s also assume the team can achieve 1 point every two hours for both design and development tasks.
If the team is achieving points according to plan, they will be earning 60 points each week during weeks 4-6. If the team does not consider the actual necessary utilization of the designer based on upcoming tasks (which is very easy to do for teams that leave all tasks pooled in a backlog instead of staging tasks for each iteration at the start of the project), the team will be incorrectly predicting project completion at ~29 weeks.
If the team was keeping a separate burn chart for developer tasks only, they would know that they have 1,140 developer points to complete and that they were only going to accomplish ~40 points each week. The team would be able to predict the likely project completion at 32 weeks.
It may not even be necessary to keep a burn chart for the design tasks because design will not be the bottleneck on the project, and inconsistent allocation will distort velocity trend lines. We’ve found success managing inconsistent project allocation by tracking average points per hour and using a simple spreadsheet table to model expected and achieved points and hours through the end of the project.
Pitfall #2 – Average Hours per Point Skew
Points-based estimates help team members estimate the relative complexity of tasks without getting bogged down in disputes around actual hours required. Over time, average points earned per week establishes a predicable velocity through the backlog and average hours per point can be calculated if you track your actual time.
We’ve tried estimating design tasks and development tasks in an apples-to-apples fashion, but we’ve found it’s often the case that design tasks are accomplished with a lower average hours per point ratio than development tasks.
Given the known average hours per point skew, let’s assume by week four the team had a backlog of design and development tasks decomposed and estimated in points totaling 1,920 (780 design points and 1,140 development points). Let’s also assume the developers can achieve one point every two hours and the designers can achieve one point for every hour.
If the team is achieving points according to plan, they will be earning 80 points each week during weeks 4-6. If the team does not consider the actual necessary utilization of the designer, they will be incorrectly predicting project completion at ~28 weeks.
Even if the team was taking the inconsistent designer allocation into account somehow, they could still be assuming they are earning one point for every 1.5 hours and projecting a weekly velocity of ~67 points instead of the 60 point reality. After several weeks of the 60 point reality, the team will start realize a delay in schedule.
A separate burn chart for developer tasks will keep the average hours per point skew from predicting an earlier delivery date.
Conclusion
Both of the simple pitfall examples above only take into account the schedule impact based on miscalculations from the first three weeks of implementation in my contrived capacity allocation model. The schedule impact can be much greater when there are more drastic capacity allocation changes or variances in task types over the course of the project.
Integrated backlogs are a great means of coordinating design and development tasks, but I recommend tagging each task type in the backlog and tracking velocity separately for the task type that is the bottleneck.