The PostgreSQL isolation level answers the question, “What should happen when one transaction tries to read or update data already updated by another transaction?” In PostgreSQL, a transaction is a unit of work that bundles “multiple steps into a single, all-or-nothing operation.” You would use a transaction, say, when attempting to insert a new record or mutate an existing record in a database.
The transaction isolation level determines what should happen when one transaction tries to read/update data updated by another transaction. There are four increasingly isolated transaction isolation levels: read uncommitted, read committed, repeatable read, and serializable. I’ll go over what each isolation level allows and doesn’t allow and illustrate those phenomena with banking transactions.
A Real-World Example
To start, let’s look at a real-world example of one process affecting another, concurrent process. Say you walk into a bank and start transferring money between accounts. If someone else (with access to your account) walks in the bank at the same time and looks up your balance, what should they see?
Should they see whatever your current balance is, even if you are mid-transfer? Or should they instead see your initial balance before you started making transfers? Should they be able to modify your balance before you have completed all of your transfers?
Now say you are building out an application that keeps track of balances in an account. You build out your database layer and start building out some business logic. Then perhaps you write a mutation to move a balance from one account to another and write a function to query an account. Let’s fast-forward and say you have built out enough actions that you are now doing multiple of these actions, each as a separate transaction, in the same request.
This is when you need to determine how much these transactions should affect each other. In SQL terms, we’re talking about the isolation level of these transactions. For instance, should you be able to update an account record while also performing a query that looks up that same account? (In SQL terms, should you allow for non-repeatable read?)
Should you allow for one action to lookup and modify a record in a table if another action is modifying that same record? (In SQL terms, is it okay if running the transactions concurrently has a different effect than running them one by one?) Basically, you’ll need to decide the isolation level for any given transaction.
Transaction Isolation Levels
Read Uncommitted/Read Committed Isolation Levels
Doesn’t Allow: Dirty Reads
Allows: Non-repeatable Reads, Serialization Anomaly
According to the SQL standard, Read Uncommitted allows for dirty reads, whereas Read Committed does not.
What is a dirty read?
Let’s start with the real-life banking example.
Piper is moving money in and out of her bank account. Let’s say she has named her account Piper’s Pennies, and she starts out with a balance of $100. Another banker, Miles, also wants to view Piper’s bank account.
This is the scenario:
- Miles walks into the bank.
- Piper walks into the bank.
- Piper starts moving her money around. She takes $10 from another account and puts it in Piper’s Pennies.
- Miles looks at the Piper’s Pennies account and sees that it has $110.
- Piper decides she moved too much money into her Piper’s Pennies account and moves $5 out of Piper’s Pennies.
- Miles leaves the bank.
- Piper leaves the bank.
Since Miles looked at Piper’s account in the middle of her transfers, the account balance he saw ($110) is not the final account balance ($105). Think of Miles’ bank visit as one transaction and Piper’s visit as another transaction. Miles looking at Piper’s account in the middle of her transfers (transaction) is similar to a dirty read. In SQL, a dirty read occurs when one transaction reads data from a concurrent uncommitted transaction.
Dirty reads are not allowed in PostgreSQL. That means the Read Uncommitted isolation level behaves exactly like the Read Committed isolation level in PostgreSQL.
The Read Uncommitted and Read Committed isolation levels still allow for Non-repeatable Reads and Serialization Anomaly. I’ll cover those in the following sections.
Repeatable Read Isolation Level
Doesn’t Allow: Dirty Reads, Non-repeatable Reads
Allows: Serialization Anomaly
Non-repeatable reads are not possible in the Repeatable Read isolation level.
What is a Non-repeatable Read?
Picture this banking scenario:
Again, let’s assume that Piper’s Pennies starts out with $100.
- Miles walks into the bank.
- Piper walks into the bank.
- Piper starts moving her money around. She transfers $10 from another account to Piper’s Pennies.
- Miles looks at Piper’s Pennies account and sees that it has $100. Miles doesn’t see the $10 Piper just put in (as Piper is still at the bank and in the middle of executing her transfers).
- Piper moves $5 out of Piper’s Pennies.
- Piper leaves the bank.
- Since Piper has finished the transfers, Miles can now see the result of her transfers. When Miles looks at Piper’s Pennies for the second time, he sees that it now has $105 ( $100 + $10 – $5 = $105).
- Miles leaves the bank.
This is not a dirty read: when Miles looks at Piper’s Pennies while Piper is still at the bank doing transfers, he doesn’t see the updated balance. Miles only sees the update once Piper has finished up her transfers and left the bank. The first time Miles looks at Piper’s balance he sees $100. The second time, he sees $105.
In one visit (transaction), Miles sees a different value when he looks at Piper’s Pennies after Piper has finished her transfers and left (made changes and then “committed the transaction”). That is essentially what a Non-repeatable read is. A Non-repeatable read occurs when a value is read multiple times during the same transaction, and the values are different because another transaction has updated the value (and committed the modification).
As a concrete example, the Read Committed isolation level allows for a Non-repeatable Read.
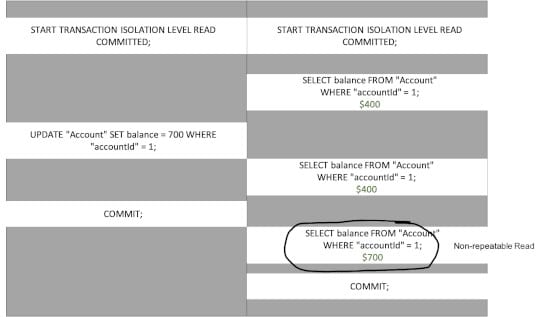
The transaction isolation level Repeatable Read does not allow for a Non-repeatable Read. This isolation level does not see uncommitted data (no dirty read) and also does not see changes committed by concurrent transactions (no Non-repeatable read).

Serializable Isolation Level
Doesn’t Allow: Dirty Reads, Non-repeatable Reads, Serialization Anomaly
Serialization Anomaly is not allowed at the Serializable isolation level.
What is Serialization Anomaly?
This banking scenario illustrates a Serialization Anomaly:
Piper’s Pennies starts out with $100.
- Miles walks into the bank.
- Piper walks into the bank.
- Piper adds $10 to her account.
- Miles looks up Piper’s account balance, he sees $100.
- Piper leaves the bank.
- Miles wants to create an account matching Piper’s balance. Piper’s balance was $100 last time Miles checked, so he creates an account with $100.
- Miles leaves the bank.
If Miles had finished up his transfers and left the bank before Piper walked into the bank, Piper would have created an account with $110 ($100 plus the $10 Piper added) instead of $100. In other words, if the visits had happened one after another, instead of concurrently, there would have been a different result.
Similarly, a Serialization Anomaly occurs when concurrent transactions result in a different state than if the same transactions been executed sequentially.
Isolation levels other than the Serializable isolation level (e.g. Repeatable Read) allow for concurrent transactions to be executed sequentially. That’s true even if executing these transactions sequentially will result in a different result than executing them one by one.

At the end of these transactions, there will be two accounts. Account 1 will have $110 and Account 2 will have $100.
Had the second transaction been executed after the first transaction, we would have gotten different results. Both Account 1 and Account 2 would have had $110.
The Serializable isolation level, however, monitors for the case where concurrent execution of transactions leads to a different result than serial execution of transactions. Because the second transaction would have led to a different result had the whole transaction been executed after the first transaction was completed, the second transaction fails.

Choosing PostgreSQL Transaction Isolation Levels
In summary, each of the above isolation levels refers to the type of phenomenons it disallows (Dirty Read, Non-repeatable Read, Serialization Anomaly).
What isolation behavior is desired depends on the situation. Let’s go back to the bank example. In some instances, it might be okay for Miles to be able to create an account with the last value he saw in Piper’s account ($100) (think Repeatable Read). However, if we wanted Miles’ new account to exactly match Piper’s account post-transfers, we would only allow Miles to create a new account after Piper had completed all of her transfers (think Serializable).