

My daughter turned 1 year old recently, and milestones like this one remind me how important my data is—especially photographs. Our family uses Google+ for photo storage and backup (which I consider very safe), but a few weeks back I started to get nervous about data loss. It can happen, even at Google.
Using physical media is an option, but what I really wanted was another cloud-based backup option that met the following criteria:
- The source is reliable and likely to still exist in 10+ years.
- I don’t need to access the data often (or ever, hopefully)—it’s insurance against catastrophic data loss.
- The service is very cheap.
Amazon Glacier Storage meets all these criteria. In this post I’ll describe how to download all your Google data (as an example) and set up an Amazon S3 Bucket with lifecycle rules that will automatically transfer your S3 data directly into Glacier storage without needing to do any programming.
Basics of Amazon Glacier Storage
So what is Amazon Glacier Storage? It is an extremely low-cost ($0.01 per gigabyte, monthly) storage service for long term online data backup. You can store anywhere from 1 byte to 40 terabytes using Glacier Storage. The catch is that accessing the data takes time (Amazon quotes 3-5 hours), and data retrieval is more expensive ($0.09 per GB). With the long access times and higher retrieval cost, Glacier is not a good choice for file staging or storage of data you need to retrieve regularly, but it’s perfect for long-term backups.
Download All Your Google Data!
Google provides a great download service called Google Takeout for documents, photos, or email. Takeout lets you download any or all of your data in zip or gzip format through their web interface.
Visit the Takeout website, select the classes of data you want to download (photos, contacts, maps, email, youtube, etc.), choose a file type for the archive, and click “Create Archive”.
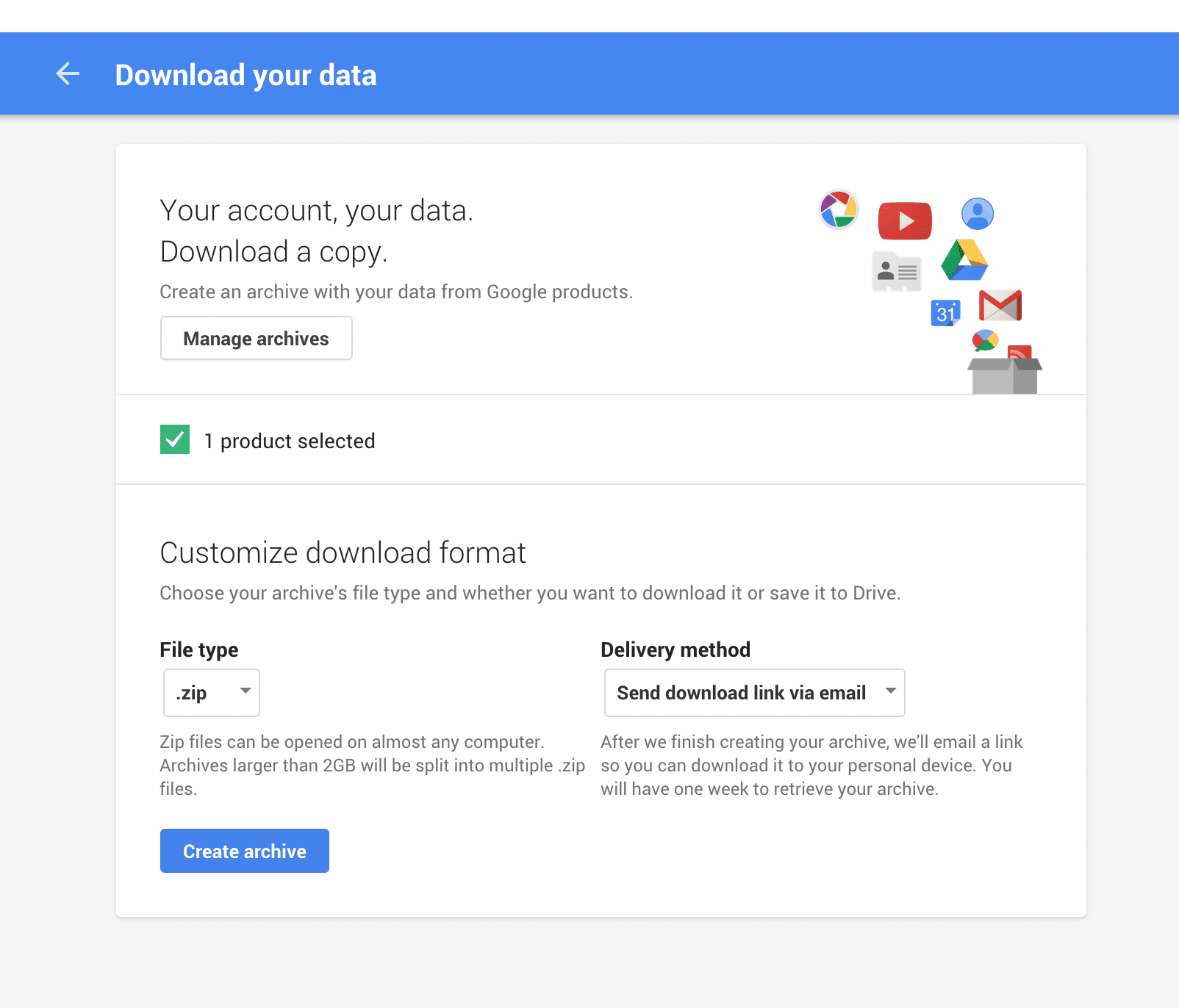
Google will create the archive for you (this takes time, but in my case a 17gb archive was ready in minutes) and you can then download the .zip files.
There are two annoying details:
- Google splits the archives into 2gb chunks, which by itself isn’t too bad, but…
- Google forces you to re-authenticate via their web interface each time you download one of the archives. They do this for data security, but not being able to batch up all the 2gb .zip files in a single download job is annoying and tedious (I had to manually download 9 archives of ~2gb a piece).
Once you have your data, it can be uploaded to Amazon.
Amazon Web Services S3 Buckets & Glacier Storage Class
To use Amazon Glacier storage, you must create an Amazon Web Services account. Amazon Web Services encompasses many different solutions: computing, storage, database, analytics, etc. We’ll be focusing on two of their storage solutions, Amazon Simple Storage Service (S3), and Amazon Glacier Storage.
Our ultimate goal is to get the data that needs to be backed up into inexpensive, long-term Glacier storage. To that end, there are three approaches:
- Use the Amazon Glacier API to write code that will upload data to Glacier. There are AWS SDKs available for both Java and .NET.
- Use a 3rd party tool like Arq, which also supports encryption.
- Configure an Amazon S3 bucket to automatically move your data to Amazon Glacier storage with Lifecycle Rules.
I am going to skip the first two approaches and explain how the 3rd can be accomplished without paying for any 3rd party software or writing any code, with four simple steps:
1. Create an AWS account.
Self-explanatory. Head over to Amazon and sign up for an account. Don’t worry, it’s free.
2. Create an S3 bucket for your backups.
Login to the AWS Management Console and select S3 under “Storage & Content Delivery.”

Once in the S3 section of AWS, click the big blue “Create Bucket” button and choose and name and region.
The key detail here is we are going to be using an Amazon S3 bucket as the container for the files we upload, then—via Lifecycle Rules on the bucket itself—have Amazon automatically move it to Glacier storage. I have found working with S3 directly is more straightforward than Glacier.
3. Add and configure a Lifecycle Rule for your S3 Bucket.
In the S3 Management Console, you should now see your new bucket under “All Buckets”, and to the left of the bucket is a Properties icon (looks like a piece of paper with a magnifying glass). Click the properties icon and Bucket Properties will open up on the right side of the screen. Expand “Lifecycle” and click “Add Rule”.
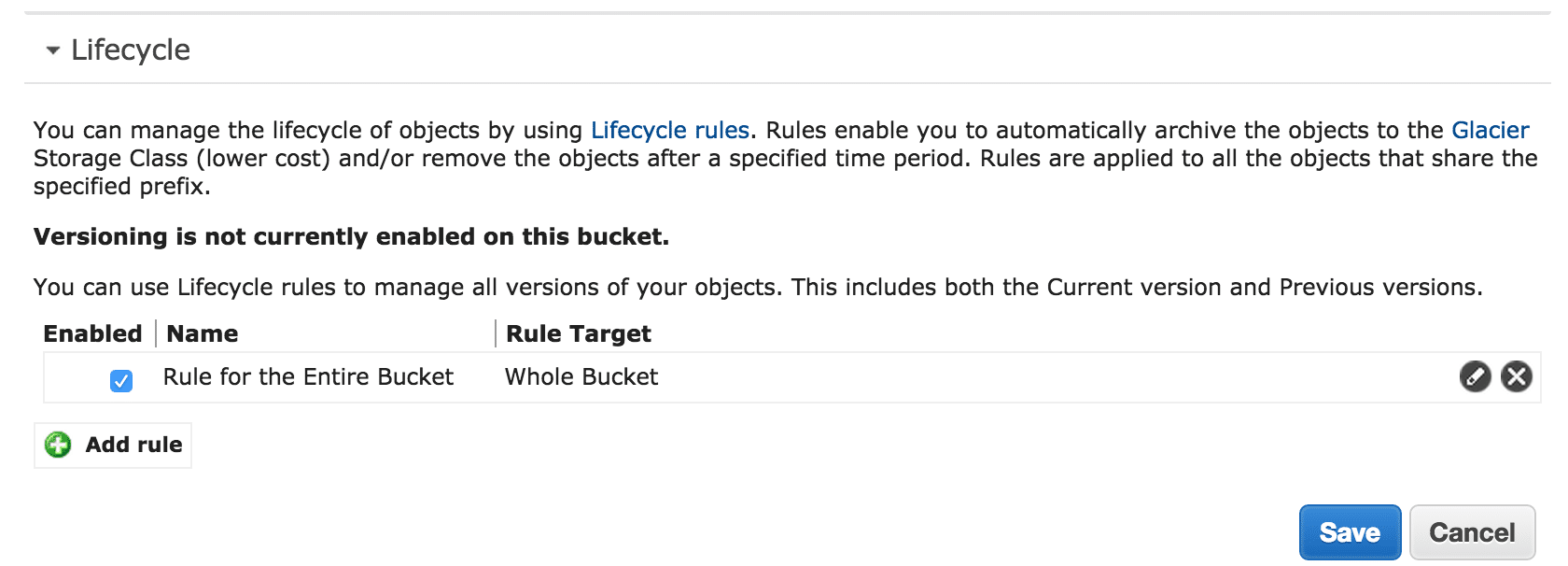
Clicking “Add Rule” opens a modal wizard for creating the rule. On the first page, select “Apply Rule to: Whole Bucket” and click the “Configure Rule” in the lower right. Now for “Action On Objects”, select “Archive Only” and enter “1 day” for “Archive to Amazon Glacier Storage Class”.

Review and accept your new lifecycle rule. Now any data uploaded to your S3 bucket will be moved to glacier automatically after 1 day.
4. Upload your data to the S3 Bucket.
There are a number of 3rd party tools for uploading and managing S3 bucket data. I used one called 3Hub (which has since been discontinued). However, it’s easy to do with the AWS Console. In the S3 Bucket console, click “Actions” and “Upload” to bring up a simple web interface for queueing and uploading files to your bucket.
Note that this approach does not encrypt your data. If that is important to you, I recommend you explore Arq.
I’ve used this method of backing up my Google data for a few months now. My plan is to just manually upload data occasionally (I’m mainly concerned with family photos). Getting my data into Glacier has given me piece of mind that even if my computer died and Google lost my data, I could get it off Glacier as a last resort.
You backup your Google data to Amazon? If there are two companies that know a LOT about data management and cloud resilience, it’d be Google and Amazon.
Are there any reasons why you think Google isn’t reliable enough for you?
Agnarr– to be honest, I tried to find examples of Google+ failing catastrophically but couldn’t find any good ones. What it comes down to is I don’t want all my data in just one place, and it’s easy enough to back it up to AWS S3/Glacier occasionally for some extra piece of mind.
The thing is, the data will probably be safe there as long as it’s not purposly deleted.
Probably.
I refer to Glacier as the “my house burned down” backup – expensive unless you lose everything, then its priceless. But I use Arq software to backup from my computer to Glacier, much easier & its automated.
That is precisely my thinking. Arq is also especially nice if you want to encrypt your data.
From AWS Glacier FAQ (http://aws.amazon.com/glacier/faqs):
So if you don’t mind AWS managing the keys, it’s technically encrypted at rest.
There is an option that AWS having the key. But this requires a KMS.
This seems like a bit of overkill to me. Backing up one cloud service to another cloud service, and both of them very big names with pretty high reliability.
If it were me and I were worried about google losing my data, i’d just back it up to my drive locally. Even though glacier is dirt cheap, doesn’t seem worth the time/money to back it up there.
Good walk thru though just in general on how to use amazon, which isn’t the most friendly of interfaces.
That’s a fair point. If Google+ has a meltdown and loses my data, it’s likely that the event that caused a catastrophe of that magnitude would also affect AWS. :-)
However, with Glacier, AWS has an obligation to keep my data around in storage (a right which I’m paying for). Google+, while I don’t expect it to go away any time soon, doesn’t have that same obligation. Anyone remember Google Reader?
That’s a fair point. I wouldn’t be too surprised if G+ goes away at some point since I don’t think it’s getting much use. Although I would be SUPER surprised if google would just delete people’s user data without giving advance warning they were going to delete stuff.
crashplan
Dropbox 1 TB subscription is cheaper than AWS Glacier. Do the math and you’ll be surprised…
That’s not necessarily true. With Glacier, you only pay for what you use. If you don’t consider download costs, Dropbox with 1TB is only cheaper when use between 825GB and 1TB. And when you go over 1TB…
Excellent KISS solution.
Several commenters have questioned the need to improve on Google’s durability of your data. Don’t get me wrong I make heavy use of Google (and Amazon’s) services both, but one thing that hasn’t been raised is the fact that either party can terminate your account per their respective Terms of Use. So a little insurance here is not a bad thing to consider.
http://www.slate.com/articles/technology/future_tense/2013/04/life_without_google_when_my_account_was_suspended_i_felt_like_i_d_been_dumped.html
(I’m the developer behind Arq the backup app you mentioned)
If you ever need to download those objects that are in Glacier storage class, please be extra careful about how much you “initiate restore” on at one time. AWS charges a “peak hourly request fee” based on how much data you’re “requesting” in parallel, so if you request a lot of things at the same time, the fee could be large. (“Requesting” or “initiating restore” means asking Glacier to make the objects downloadable, and takes about 3-5 hours). Check the AWS Glacier FAQs for details on the fee.
To avoid a large fee, initiate restore on some data, then wait 4 hours, then initiate some more while you download the stuff that has become available. (Arq does exactly this when you restore a large amount of data; you choose the transfer rate, and it manages the initiating.)
Stefan, thanks for the comment. Arq looks like a fantastic tool, especially for people who want to automate this process and have more control over the security of their data.
How much about are you paying for your 9GB of storage with Glacier? Do you just store one backup or do you just upload the delta of your current backup and your last backup?
I have a huge amount of photos that I’d like to securely store but have a huge dedupe process to overcome!
Hi Daniel. I just checked, in the post I mis-spoke and I actually have ~ 16gb stored on glacier.
So the cost is currently $0.16 per month. Here’s a screenshot of my billing page:
http://snag.gy/Pxz2Q.jpg
Dang! They are gouging you! ;) I’d definitely pay $0.10 for peace of mind.
Any recommendations on your dedupe / dated back up process? Or do you just delete the old one and replace it with the new one every time?
That’s not necessarily true. With Glacier, you only pay for what you use. If you don’t consider download costs, Dropbox with 1TB is only cheaper when use between 825GB and 1TB. And when you go over 1TB…
I’m always curious why people think a thing is cheap (or expensive). $.01/GB/month seems not very cheap to me: compared to a basic consumer 3-year warranty disk, it would be like paying $360/TB. Current street prices are more like $50/TB (power is inconsequential). The only way I can interpret this is that the “other stuff” is why Glacier seems cheap to the author: someone else manages it, worries about it failing, powers and cools it, makes it available online.
Of course, the same applies to EC2, which costs about the same as buying your hardware new each year.
So the conclusion here is that mostly people want to pay for someone else to do the hardware, and are willing to pay big for it. That’s not totally surprising, but it is a little: why do people find hardware so aversive? I think it’s just that they don’t know hardware.
Mark – i can’t speak for everyone but for most people aware of what a backup is supposed to do, it’s cheap because it’s an ‘offsite’ backup. Using your own hard drives to backup your files is great – unless there’s a fire and your house burns down, or someone breaks into your home and steals your drives etc
So i think for people who really understand the purpose of a backup, that’s why it’s considered cheap and why people upload things to the cloud. It’s an offsite backup that protects you against any sort of physical disaster.
Another possibility is that people don’t realize they can stick another hard drive into their computer. Most people I’m sure buy a computer and never open it up or are aware they can open it up and install additional components.
Plus with some cloud storage, like dropbox, you have the advantage of being able to access your files remotely and/or share them with other people. You could do that if they are stored on your pc, but it’s not as easy to setup/as user friendly as using dropbox.
I wish Google would provide an API to takeout so it could be scheduled.
I agree, that would be fantastic. Their reason for making the takeout service so cumbersome is ‘security’- I’m skeptical.
Hi,
How do you plan on retrieving your backups using your approach? Is it possible to move it back to S3 and then fetch from there?
Be aware that different tools have different filename schemes so sometimes the files will come back with garbled filenames if you retrieve them using another tool than you used for the backup.
Regards,
Martin
Hi Martin,
I haven’t retrieved data from Glacier yet, but you have to make a request from Amazon and it takes ‘several hours’ before the data is ready. Here’s the FAQ on the topic:
http://aws.amazon.com/glacier/faqs/#data-retrievals
Just stumbled across this. I was using S3 in a similar way, but in the end I switched to Fastglacier (Windows app) for ease of use and the ability to do a folder compare and upload.
What has thrown me off is the unlimited amazon photo backup service for $12.
Considering fastglacier was $40 and I get charged about 26c per month from Amazon (and getting slightly more expensive each month), $12 is not too bad for unlimited.
Throw in data charges, charges for access, slow retrieval time and no sharing options or smartphone upload it really does make glacier not as attractive as it once was.
Id lose the file compare that I currently have (unless they Amazon’s desktop app has that as well), but there will come a point where it will overtake Glacier as the cheaper photo backup.
Ok 26c or $12 isnt breaking the bank, but other features are very compelling.
For now, im still sticking with Glacier, but I think the clock is ticking for this option.
Great article John!
Do you know if is possible to backup only .JPG file to Glacier?
I currently have a Synology NAS running a Amazon app, but couldn’t find out.
Thanks in advance,
Teixeira, Thiago – Brazil
I used a site and expand my free Dropbox from 2 gb to 18 gb. Got it forever, with no monthly payments :) Google this: “dropbox 18 gb”. The first site does the job.