Article summary
Projects are full of features. As an agile shop, we believe in getting those features in front of our client and end users as soon as they have been completed and thoroughly tested. It allows us to validate our assumptions and iterate on the feature if necessary. However, after an application is in production things become trickier.
After a project goes into production and the user base begins to grow, the client’s deployment strategy will change because they need to market their new features. They may also decide that some features need to be withheld for a feature release. This makes the traditional agile workflow of “delivering features as they are finished” difficult.
So, how do we continue to deliver value to our client and customers and sit on completed features? On a recent project, we’ve tried two different strategies and I want to share the strengths and weaknesses of both.
Strategy 1: Release Branches
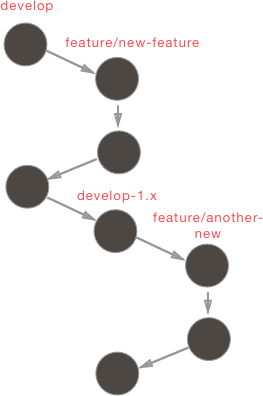
The exact workflow we are using on this project closely follows gitflow. There are a couple important gitflow concepts to be familiar with:
- All code on
masteris what is currently deployed to production - All completed features that have not been released are on
develop - All features are developed on
feature/feature-name
This workflow is great when you’re confident that everything on develop will be deployable in the next release. It also allows us to test our entire codebase often as tests run each time a commit is made.
But, what happens when development is ahead of the release schedule and new features need to be intentionally withheld?
This is where release branches come in. The idea is very similar to the gitflow model, except that now we have multiple develop branches. For example, our next release lives on develop and the following release would be on develop-1.x.
Here is what the version control system looks like under this model:

Pros
- Clear separation of features
- No technical debt of feature flags
Cons
- Rigid releases
- Difficult to maintain when supporting 3 or more releases
- Error prone (e.g. merging into the wrong branch, branching off wrong release)
This model actually works pretty well when you are managing up to 2 releases. It forces you to think ahead about which features fit nicely together in releases, and when the number of releases is low, there is a much lower chance of branching from the wrong base branch or merging to the wrong base branch.
But, it starts to fall apart when we are managing more releases or when the customer decides to sit on a feature that was previously approved. This is where the second strategy comes in.
Strategy 2: Feature Flags
Feature flags are not a new concept. You can google the idea and find countless blog posts on the topic. The basic idea is that each new feature gets hidden behind a flag that can be toggled to enable or disable the feature.
This means that we no longer need multiple develop-1.x branches. As long as each feature is hidden behind a flag, all of our code can continue to live in one place.
Here is the branching model of this system:

Pros
- Highly configurable releases
- All code lives in one place
- Fewer branches to maintain
- Adds possibility of A/B testing
Cons
- Technical debt of feature flags
- Need discipline to remove feature flags
There are quite a few benefits to this approach. As the application becomes more successful, the client can use feature flags to deploy new features to a subset of users. For developers, the code lives in one place, on develop. We can also have a more flexible release schedule and on top of that, we can easily turn a feature off if it doesn’t work as expected.
As you can see, both of these models have their benefits and drawbacks. We have recently gone from the release branch model to the feature flag model and we have found that the wins far outweigh any of the complications.
I would love to hear how others have managed releases in live applications.
I’ve shifted to feature flags as well, especially for features in the front end that won’t be supported by the back end for a while.
I tend not to remove feature flags after the fact, as it allows you to turn off features very easily when they cause problems. GitHub uses feature flags to let them partially bring down the site for maintenance or troubleshooting.