Article summary
Scrum-like Agile project management gives teams many tools for projecting progress and timelines. At Atomic, we diligently track budget and scope, but I’ve seen teams struggle with understanding the full scope of significantly complex projects early enough to make course corrections.
Scope projections should be developed early and updated often, until the team has a fully defined and estimated backlog of work. In this post, I’ll explain a simple scope projection method I’ve used to manage expectations and track progress in the face of significant uncertainty.
When the Strength of Velocity Fails
We develop a lot of large, complex projects at Atomic. When planning a large project, our clients usually want to get started with implementation as soon as possible. The problem is, significant research, design, and planning (RDP) needs to occur before developers can get started responsibly. In these cases, we occasionally end up with a hybrid approach:
- An RDP phase starts early with a lead designer, technical lead, and Delivery Lead.
- As the backlog begins to take shape (several sprints worth of work are well defined), the development team starts implementing.
- RDP continues in parallel with development: wireframing, validating designs with our clients and users, and creating visual design.
This plan works well for getting started quickly and responsibly. However, the typical Agile method of comparing team velocity against total project scope to measure progress fails. We have a team velocity, but the total scope is unknown and may remain unknown for a significant amount of time.
This happens for a variety of reasons: user testing or stakeholder alignment takes longer due to clients’ busy schedules, the project is so large that it’s not practical to design all features prior to kicking off development, or we need to start early enough to hit a hard deadline.
Projecting Total Scope
I’ve tried several broad approaches to modeling/projecting total project scope:
1. Budget modeling
During our sales process, Atomic’s upfront team will meet with prospective clients and develop a budget model that considers several data points and determines a recommended budget range. We work with our clients to identify a fixed budget within that range that feels responsible to us and works for them from a value standpoint. I recently wrote a blog post on this subject.
We determine budgets upfront in the sales process. What we’re building invariably changes once the RDP and development phases are underway, so using the budget model isn’t a good choice for estimating scope.
2. The backlog
We like to use Pivotal Tracker to manage the Agile development process on our projects. A backlog of sprintable stories is great for capturing and estimating well defined work. I’ve also tried to use it to estimate complexity of less well-defined work by creating “placeholder” stories that aren’t sprintable and asking the development team to give them gut-level estimates. Unfortunately, this approach hasn’t worked well:
- Once estimated, story points usually aren’t adjusted. Scope projections should be flexible and communicated to clients regularly.
- Default pointing schemes aren’t flexible enough, usually being powers of two or Fibonacci (however, they can be customized).
- Developers are often focused on technical implementation and feel less empowered to adjust the scope of an unknown story based on their understanding of value to the client (that’s one of the responsibilities of our Delivery Leads).
- Developers feel keenly responsible for hitting estimates, even if they aren’t time based, and they often (understandably) over-compensate by estimating conservatively.
The above problems aren’t fatal, but they get in the way and cause unnecessary friction and wasted time. I’m convinced the backlog isn’t the right tool for the job.
3. Relativistic projections
Instead of asking the development team to put a points estimate on a placeholder story, I’ve moved the projections out of the backlog and created a simple spreadsheet that uses a relativistic approach.
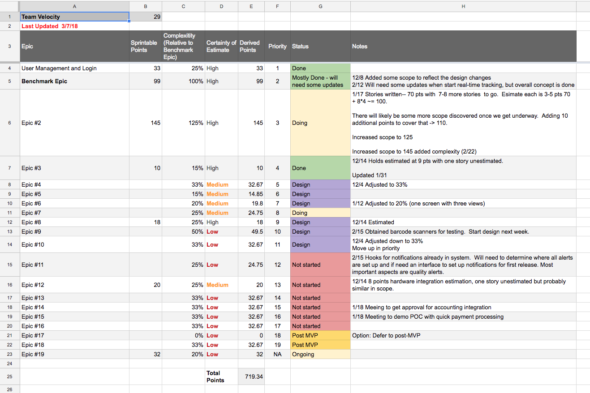
The approach is as follows:
- Start with a moderately complex Benchmark Epic and define/estimate it fully in the backlog as soon as is responsible (in the spreadsheet, its shown on Row 5). Input actual backlog points estimates in Column B.
- List all other epics. In Column C, add a gut-feel, percentage-based estimate of complexity relative to the Benchmark Epic. Projected points are
the benchmark's actual points*relative complexity. - As epics are defined in the backlog, add their actual points in Column B. If an epic has actual backlog points, the actual value overrides the gut-feel estimate relative to the benchmark.
- Sum the derived points (Column E) to get the total projected scope.
- Update the spreadsheet weekly and review with clients at least bi-weekly.
On Step 2, I involve design and technical leads and keep the discussion carefully time-boxed. The goal of the gut-feel relative estimate is to get a reasonable feel for complexity quickly. Be sure to communicate to your team that your client knows these aren’t promises, and you will continue to tweak them over time.
I’ve also found it useful to add a measure for certainty of the estimate (Column D), priority (Column F), status (Column G), and notes (Column H). These are all talking points to cover when you review the sheet with your client or key stakeholder.
Finally, capture the projected scope on a burn chart. I include a dashed line to communicate the projected scope, and I update it every sprint to show clients and key stakeholders how that scope changes as we define the project.
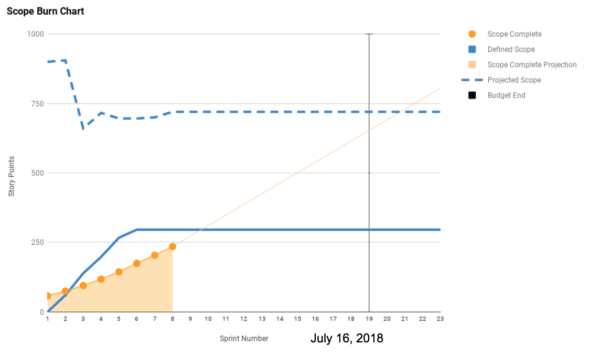
Remember that scope projections are just that—projections of what we believe the total scope to be that this point in time. They aren’t fully-defined user stories.
By updating the spreadsheet regularly and communicating with your client, you can avoid unhappy surprises and empower clients to make decisions earlier. This approach also avoids the risk of getting bogged down in choosing a perfect estimate. I’d love to hear your solutions to this tricky problem!
Hi John,
it will be interesting to know about the time planning horizon and how accurate is your initial estimates after project completion. I presume you are using average story points. In my experience, i was able to schedule in time (not in story points) after 50% of the project completion. I noticed four factors influence the estimates:
1. team maturity in terms of experience,
2. subject matters experts contribution (so the team will be able to understand from the beginning the business wide scope and any integration with other systems).
3. Confidence level with the technology stack (and especially if team is using a new language or a new framework).
4. Operational support. If the deployment into production follows the sprint cycle, the team will start to deal with issues in production, Even if these defects go back to the backlog, the availability of the team for new development goes down a little bit
Thanks
Kostas
Kostas,
Yep, I used overall points for a given epic (row) in the project, then scaled other epics based on gut feel and considerations you astutely laid out in your comment (I agree that items 1-4 are all valid and should be considered when making the relative estimate).
My goal was (1) to get a model for estimating total scope up and running quickly, in the face of significant uncertainty and (2) build it in such a way that it evolves over time as our understanding of the project matures.
Having used it on a couple projects, I’ve found that the estimate “settles down” around the 30-50% completion mark, depending on project risks that fall outside of the team’s control. Accuracy is harder to judge, but it felt like the data coming from this tool was helpful for high-level analysis of whether or not we were on track.