Article summary
While rewriting some validation logic recently, I got to thinking about how “validation” tends to be an umbrella term that covers related, but distinct, operations. So I went back to the basics in order to find more accurate terminology for each step of the process.
On its own, the term “validate” can be a bit ambiguous. Does it just mean reject invalid input? Clean up the input so that it becomes valid? Something else?
I realized that the operations involved in validation generally include transforming input and accepting/rejecting input. Making different combinations of each of these led me to the following terminology and diagram.
Terminology
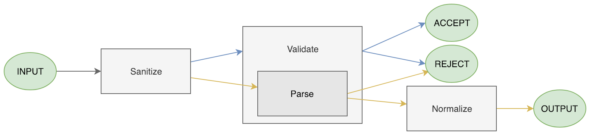
Sanitization
- Transforms: yes
- Accepts/Rejects: no
Input frequently comes in a little messy (e.g. trailing whitespace). When it comes to validation, stricter is better, but some messes can and should be cleaned up first.
Sanitization does not include the possibility of rejecting input, and the output of this step may still be invalid. The goal is just to improve the odds of passing validation. And depending on the complexity of the input, this step might be rolled into parsing.
There’s another kind of sanitization that I think does not belong here. It’s the kind that makes a value “safe” for a specific context–for example, escaping user input for an SQL query or removing HTML tags. The process I’m describing is more about input, whereas this second kind of sanitization is more about output.
Validation
- Transforms: no
- Accepts/Rejects: yes
At this stage, validation is simply determining whether a value is acceptable according to a strict definition. It’s often written in terms of whether an attempt to parse succeeds or fails (for example, TryParse methods are common in .NET; they return a Boolean indicating success, as well as the parsed value). This also helps to keep the source of truth about what is valid in a single place.
Parsing
- Transforms: yes
- Accepts/Rejects: yes
The process of parsing is an attempt to extract a value or structure from an alternative representation (e.g. an HTML document) or looser format (e.g. a phone number). If the parse succeeds, the result is a transformation of the input. If it fails, the input is usually rejected outright, although it could also result in a partial success with warnings.
When parsing structured data, you might have separate notions of “well-formed” vs “valid.” For example, an XML document is well-formed if it contains correct XML syntax, but it still may not be valid according to its document type definition (DTD).
Normalization
- Transforms: yes
- Accepts/Rejects: no
Normalization has the same signature as sanitization, but a different motivation. Whereas sanitization seeks to remove meaningless characters from the input, normalization seeks to produce a standard output. As a result, it is normally applied after validation.
Conclusion
As usual, naming things is difficult. However, there is value in coming up with terminology that is specific rather than broad, and then using that terminology consistently. The terminology I’ve defined here may not apply to all projects, but at least within my own project, it will more clearly communicate the intent of different sorts of validation.