I recently finished the book “Antifragile” by Nassim Taleb. The book outlines three categories for classifying how things respond to disorder. Taleb defines them as fragile, resilient, and a new term coined antifragile. The book also exhausts examples of using this classification system in different domains. In this post, I apply this classification system to a domain I am familiar with: antifragile cloud architecture.
Disorder can emerge in many different forms. Concerning cloud architecture, it could be a security breach, an unexpected software error, or unexpected high request throughput. For this post, high request throughput, or stress for short, is the primary factor I consider in each of the styles of cloud scaling architectures below.
Fragile: Vertical Scaling
Something fragile can only withstand so much stress before hitting a breaking point with no return to stability without outside intervention.
Vertical scaling is the response to stress of adding more computing resources to a single server. This could mean upgrading to a processor with more cores or adding more memory to the server. Essentially, better hardware means more capacity for handling workloads.
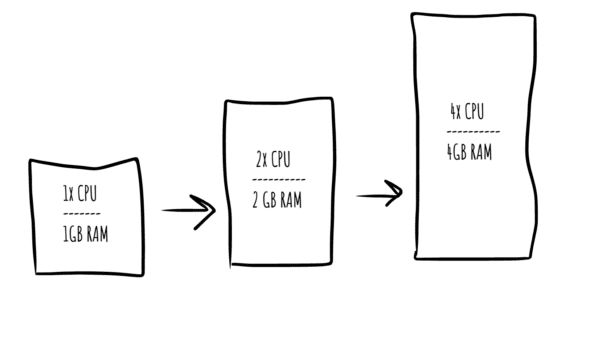
This technique is fragile because it is non-redundant. That means when a vertically-scaled server is using all its resources, users will experience degraded performance, if not a complete outage. And adding more computing resources is usually not something you can do on-the-fly as it requires provisioning a new server with more resources and then cutting over the stressed server to the new one.
Resilient: Horizontal Scaling
Something resilient is capable of bouncing back from stress and returning to a stable baseline.
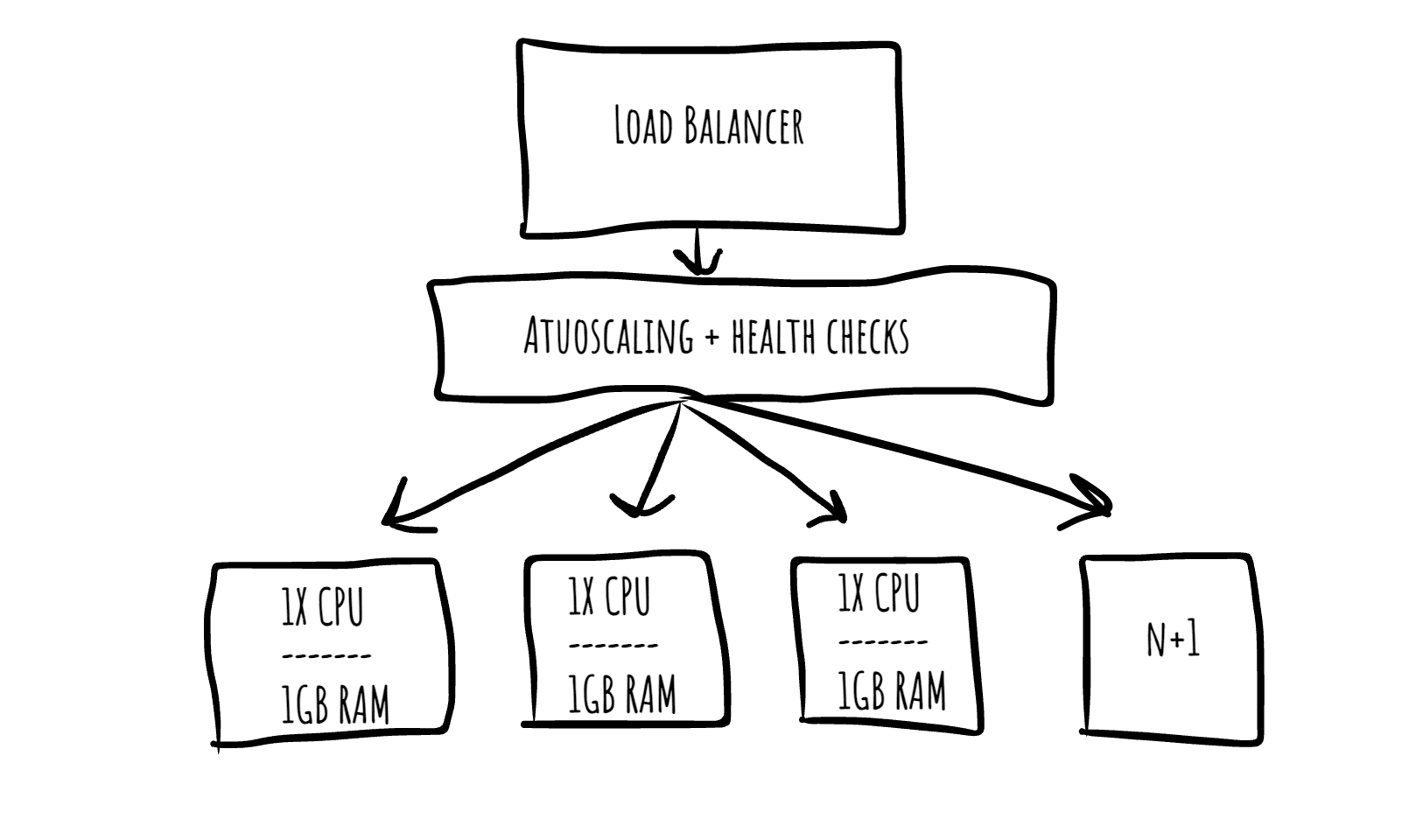
Horizontal scaling is the treatment where server hardware resources typically stay the same (as opposed to vertical scaling). However, more servers are added behind a load balancer to process the workload. In this scenario, capacity increases with the number of servers.
You can consider this type of scaling resilient because it is redundant. Redundancy is usually a good thing to have in the event of disorder. Here’s a quote from Nassim in regard to this point:
“Redundancy is ambiguous because it seems like a waste if nothing unusual happens. Except that something unusual happens — usually.”
So, in the usual event of something unusual happening, a horizontal system can more easily recover than that of vertical scale. Take, for example, a web request that triggers an unintentional memory leak on the server, leading to out-of-memory errors. In the single vertical scale architecture, the server will seize up. It will no longer be able to process work due to no memory, causing an outage. The horizontal architecture will suffer less harm because it will only seize up one server of the many, allowing work to continue, albeit inhibited.
Scaling horizontally will still have a capacity limit just as vertical scale does. However, it is usually easier to add capacity to this architecture because the server unit is predefined, you just have to add more of them to increase capacity. There is no figuring out processor cores, amount of memory, etc. It’s more or a matter of simple math. For example, if there are two servers and the current workload is using 100% of capacity, add one more server unit, and you’ll add 50% more capacity.
Antifragile: Horizontal Autoscaling
Antifragile cloud architecture will still experience harm from stress, but it will bounce back and benefit from it in the long run.
Autoscaling is an automated extension of horizontal scaling. Instead of manually adding servers to increase capacity, it can be done automatically.
I argue that applications running on this style of infrastructure get better in the event of stress because capacity adapts to changes in workload. The system will be self-healing and not require manual intervention based on throughput levels. This means your applications could experience a 10 times (or more) burst of traffic, and you can be sipping mezcal oceanside without the worry of the application going down due to traffic (in theory). Or, even if a server experiences an unusual error, auto-scaling architecture would know how to handle a bad server unit and replace it with a healthy one. That’s antifragile cloud architecture.
Autoscaling does have its limits, however. There is usually a point where a supporting system maxes out. This puts a cap on autoscaling, requiring intervention. You can experience benefits from scaling out up until the point of your next bottleneck. This could be a database, key-value store, load balancer, etc. For example, if a database is running at 100%, adding more capacity to handle web requests will not add benefit. that’s because web requests can only be processed as fast as the slowest systems in the process, or the database in this example.
This is my take on applying Nassim’s ideas to cloud architecture. Can you think of any other cloud architecture characteristics that can be added to one of these categories?