Article summary
When developing a website, you might be interested in understanding how well search engines can crawl and understand it. Google offers a tool called Fetch as Google that can help answer that question.
In this post, I’ll explain how to use Fetch as Google to test your website. It can be used for any website; however, I’m going to focus on testing the SEO visibility of React applications, as I am currently working on a public-facing React web app.
Single-Page App SEO
The move toward single-page applications (e.g., React, Angular, Ember, etc.) has changed how content is delivered to users. Because of this, search engines have had to adjust how they crawl and index web content.
So what does this mean for single-page application SEO? There have been several great posts that attempt to investigate this. The general takeaway is that Google and other search engines can crawl and index these applications with pretty good competency. However, there can be caveats–so it’s really important to be able to test your site. This is where Fetch as Google comes in.
In Google’s own words:
The Fetch as Google tool enables you to test how Google crawls or renders a URL on your site. You can use Fetch as Google to see whether Googlebot can access a page on your site, how it renders the page, and whether any page resources (such as images or scripts) are blocked to Googlebot. This tool simulates a crawl and render execution as done in Google’s normal crawling and rendering process, and is useful for debugging crawl issues on your site.
A Simple React App
To experiment with Fetch as Google, we’ll first need a website (React app for us) and a way to deploy it to a publicly accessible URL.
For this post, I’m going to use a simple “Hello, World!” React app, which I’ll deploy to Heroku for testing. Despite the app being simple, the concepts generalize well for more complicated React apps (in my experience).
Suppose our simple React app looks like this:
class App extends React.Component {
render() {
return (
<div>
<h1>Hello, World!</h1>
</div>
)
}
}Using Fetch as Google
You can find the Fetch as Google tool under the Google Search Console. (You’ll need a Gmail account to have access.)
When you arrive at the Search Console, it will look something like this:
The Search Console first asks for a website. My Heroku app is hosted at https://react-seo-demo.herokuapp.com/. Enter your website URL and then press Add a Property.
The Search Console will then ask you to verify that you own the URL that you would like to test.
The verification method will vary depending on how your website is hosted. For my site, I needed to copy the verification HTML file provided by Google to the root directory of my website, then access it in the browser.
After verifying your URL, you should see a menu like this:
Under the Crawl option, you should see Fetch as Google:
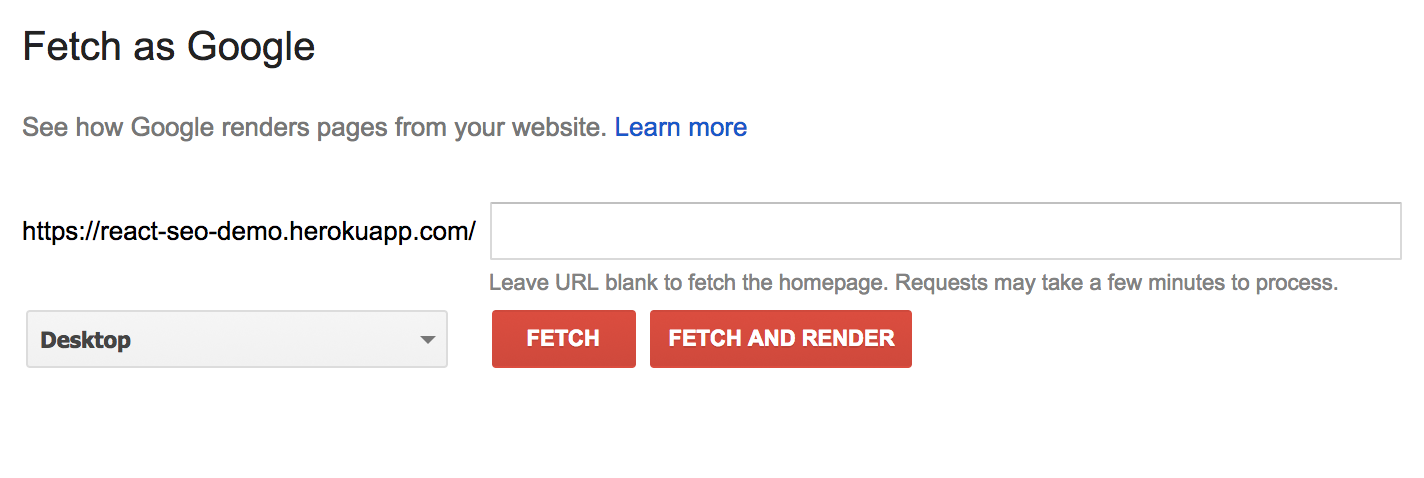
Fetch as Google allows you to test specific links by specifying them in the text box. For example, if we had a /users page and wanted to test that, we could enter /users in the text box. Leaving it blank tests the index page of the website.
You can test using two different modes: Fetch, and Fetch and Render. As described by Google, Fetch:
Fetches a specified URL in your site and displays the HTTP response. Does not request or run any associated resources (such as images or scripts) on the page.
Conversely, Fetch and Render:
Fetches a specified URL in your site, displays the HTTP response and also renders the page according to a specified platform (desktop or smartphone). This operation requests and runs all resources on the page (such as images and scripts). Use this to detect visual differences between how Googlebot sees your page and how a user sees your page.
Running a Fetch on our test React site yields:
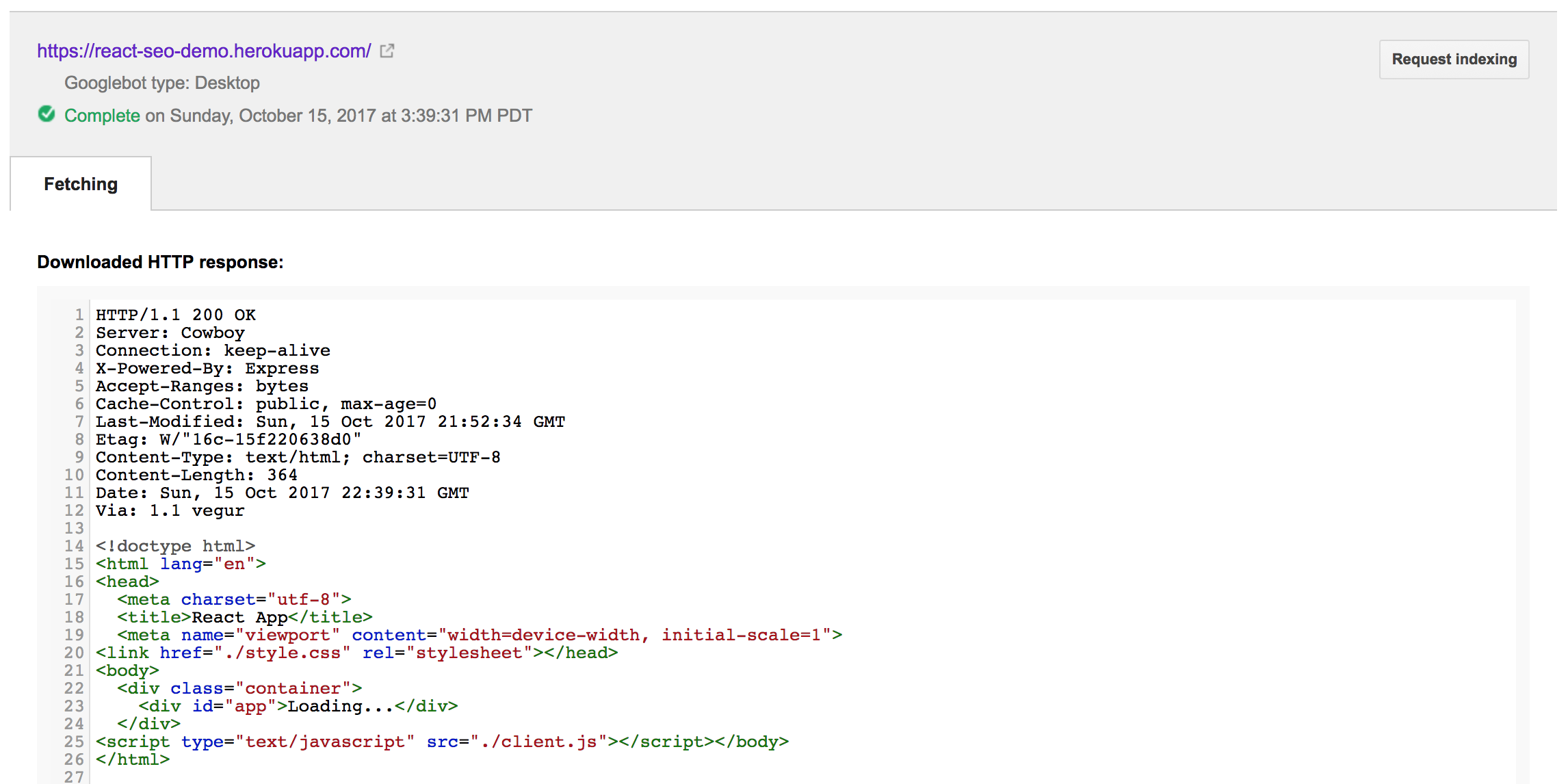
This reflects the index.html page housing our React app. Note that this reflects the HTML when the page loads, before our React app is rendered inside of the app div.
Running Fetch and Render yields:
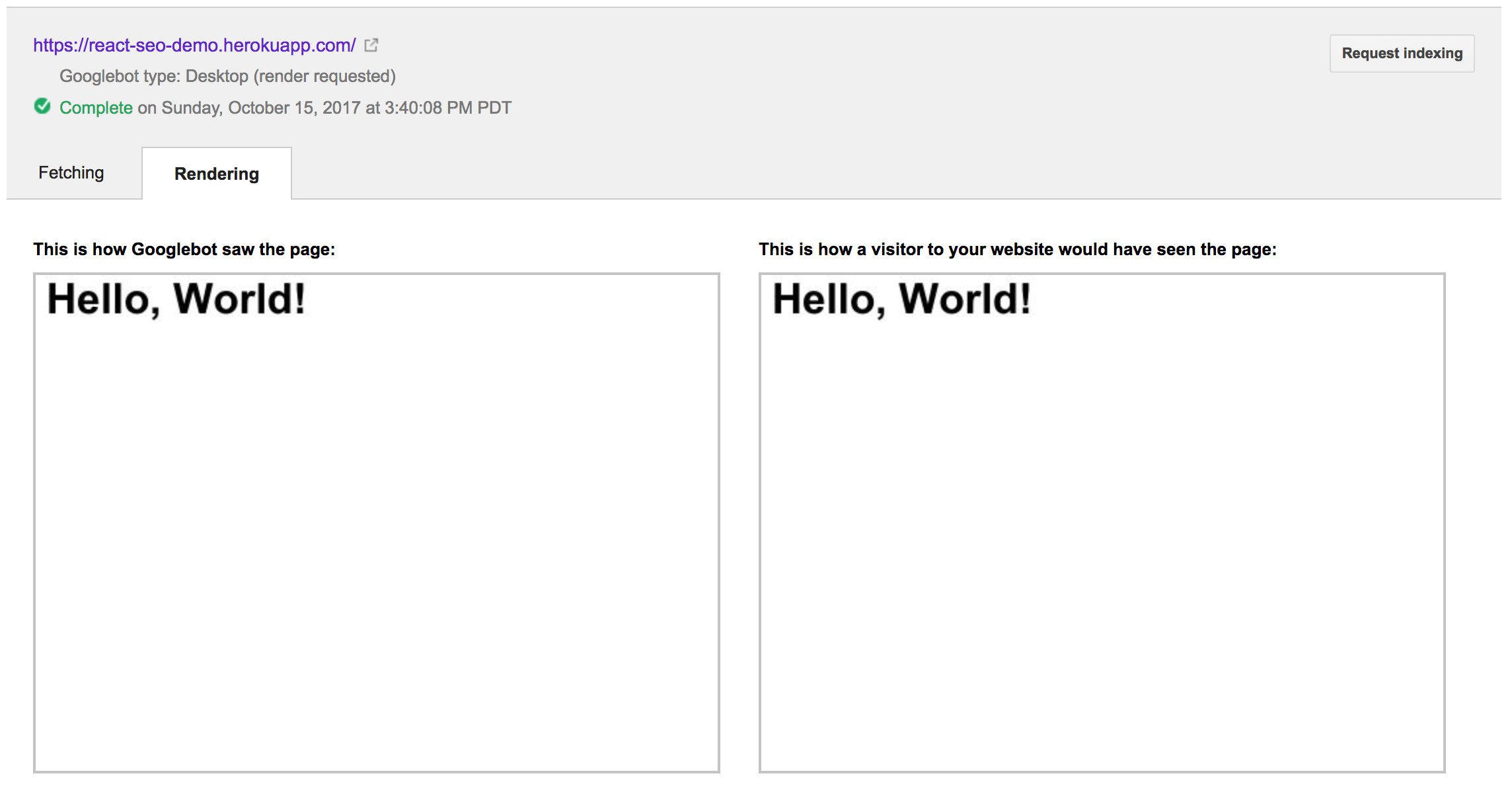
This provides a comparison of the site that the Googlebot is able to see with what a user of the site would see in their browser. For our example, they are exactly the same, which is good news for us!
There are several stories on the internet of folks running Fetch as Google on their React apps and observing a blank or different output for “This is how Googlebot saw the page.” That would be an indication that your React app is designed in a way that is preventing Google, and potentially other search engines, from being able to read/crawl it appropriately.
This could happen for a variety of reasons, one of which could be content that loads too slowly. If your content loads slowly, there is a chance that the crawler will not wait long enough to see it. This wasn’t a problem in our above example. I’ve also run Fetch as Google on a reasonably large React website that makes several async calls to fetch initial data, and it was able to see everything just fine.
So what’s the limit? I decided to run some naive experiments.
Experiments
Note: I’m not sure how Fetch as Google works under the hood. There are some posts that hint that it might be rendering your website using PhantomJS.
React apps usually rely on asynchronous calls to fetch their initial data. To reflect this, let’s update our sample React app to fetch some GitHub repositories and display a list of their names.
class App extends React.Component {
constructor() {
super();
this.state = { repoNames: [] };
}
componentDidMount() {
let self = this;
fetch("https://api.github.com/repositories", {method: 'get'})
.then((response) => { return response.json(); })
.then((repos) => {
self.setState({ repoNames: repos.map((r) => { return r.name; })});
});
}
render() {
return (
<ol>
{this.state.repoNames.map((r, i) => { return <li key={i}>{r}</li> })}
</ol>
)
}
}Running the above through Fetch as Google produces the following output:
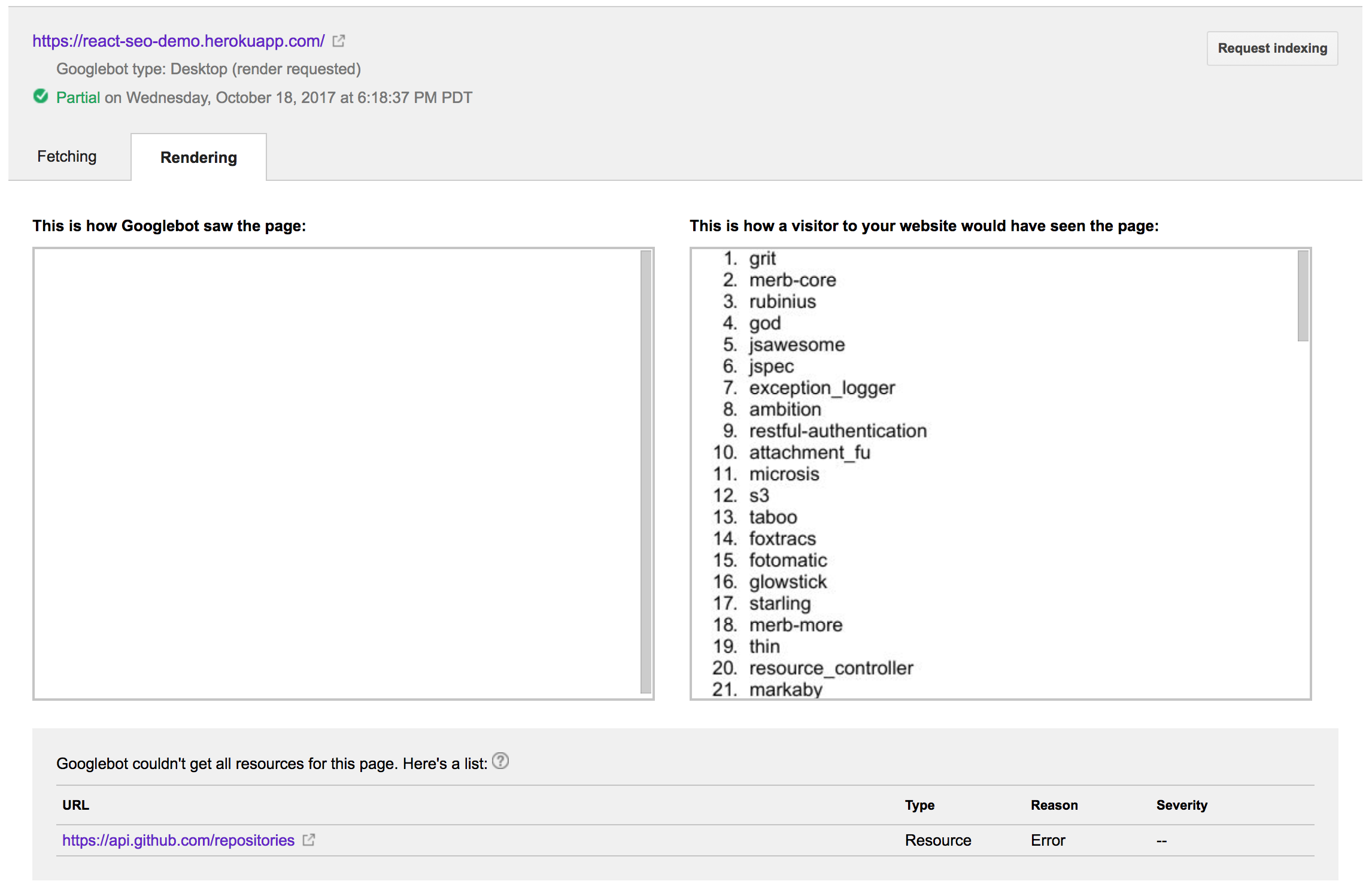
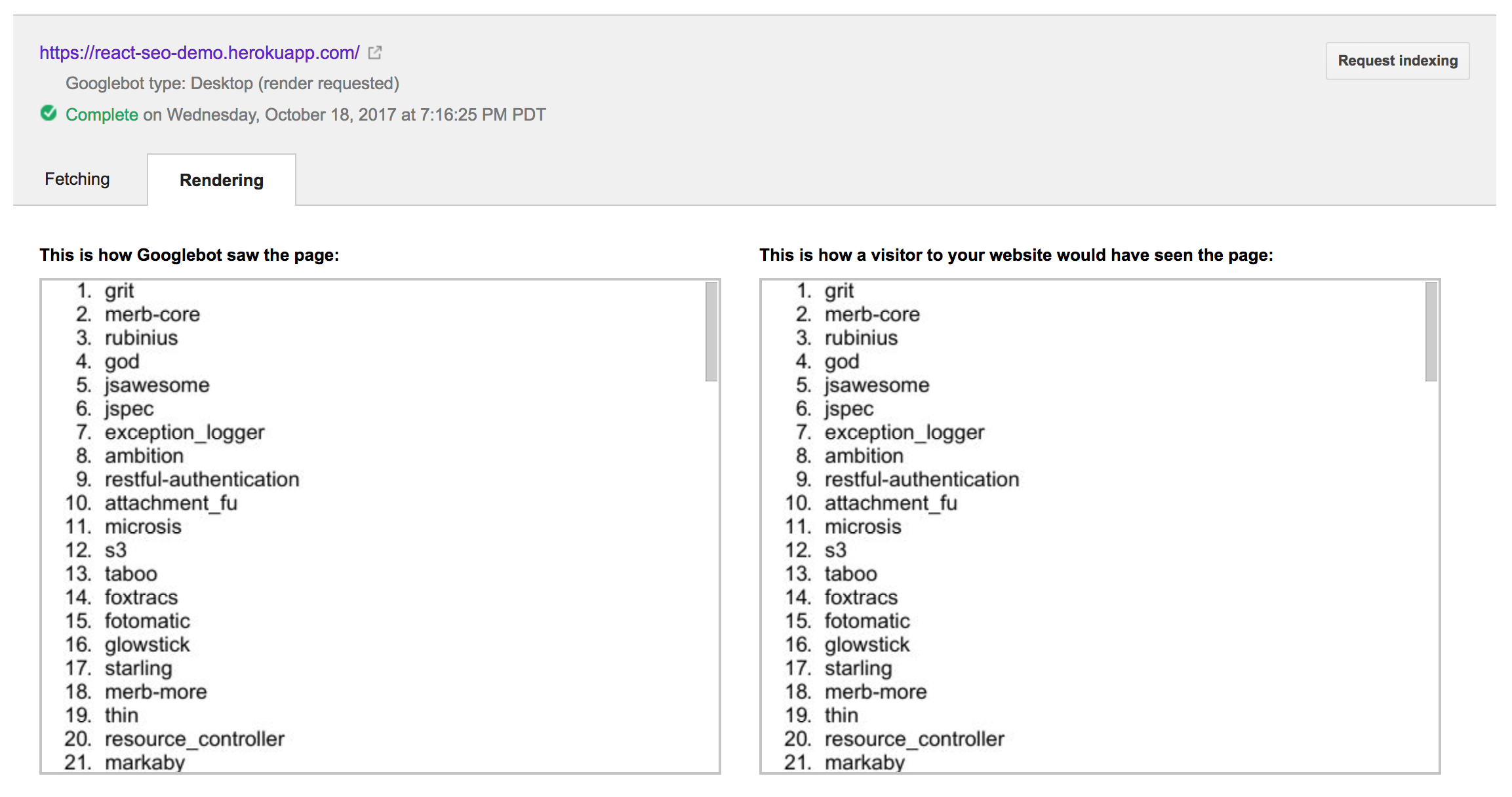
Oh no! It wasn’t able to see any of the data from the async call to GitHub. I’ll be honest; this confused me for a bit. At first I thought it might be some strange cross-origin restriction. However, it turns out the Googlebot can process cross-origin requests just fine. After some digging, lots of trial and error, and a but of luck, I discovered that I needed to include an ES6 Promise polyfill. Apparently the browser that the Googlebot runs in doesn’t include an ES6 Promise implementation. After bringing in es6-promise, the Fetch as Google output looked like this.
Let’s pick at Fetch as Google a bit more. Suppose that your application has a slow call, or some async processing that it does–using things like setTimeout or setInterval. How long will Fetch as Google wait around for these types of async requests, and when will it capture its snapshot of your website?
Let’s modify our “Hello, World!” app from above to wait five seconds before displaying the “Hello, World!” text:
class App extends React.Component {
constructor() {
super();
this.state = { message: "" };
}
componentDidMount() {
setTimeout(() => {
this.setState({
message: "Hello World!, after 5 seconds"
})
}, 5000);
}
render() {
return (
<div>
<h1>{ this.state.message }</h1>
</div>
)
}
}Running Fetch as Google with the above code yields this:
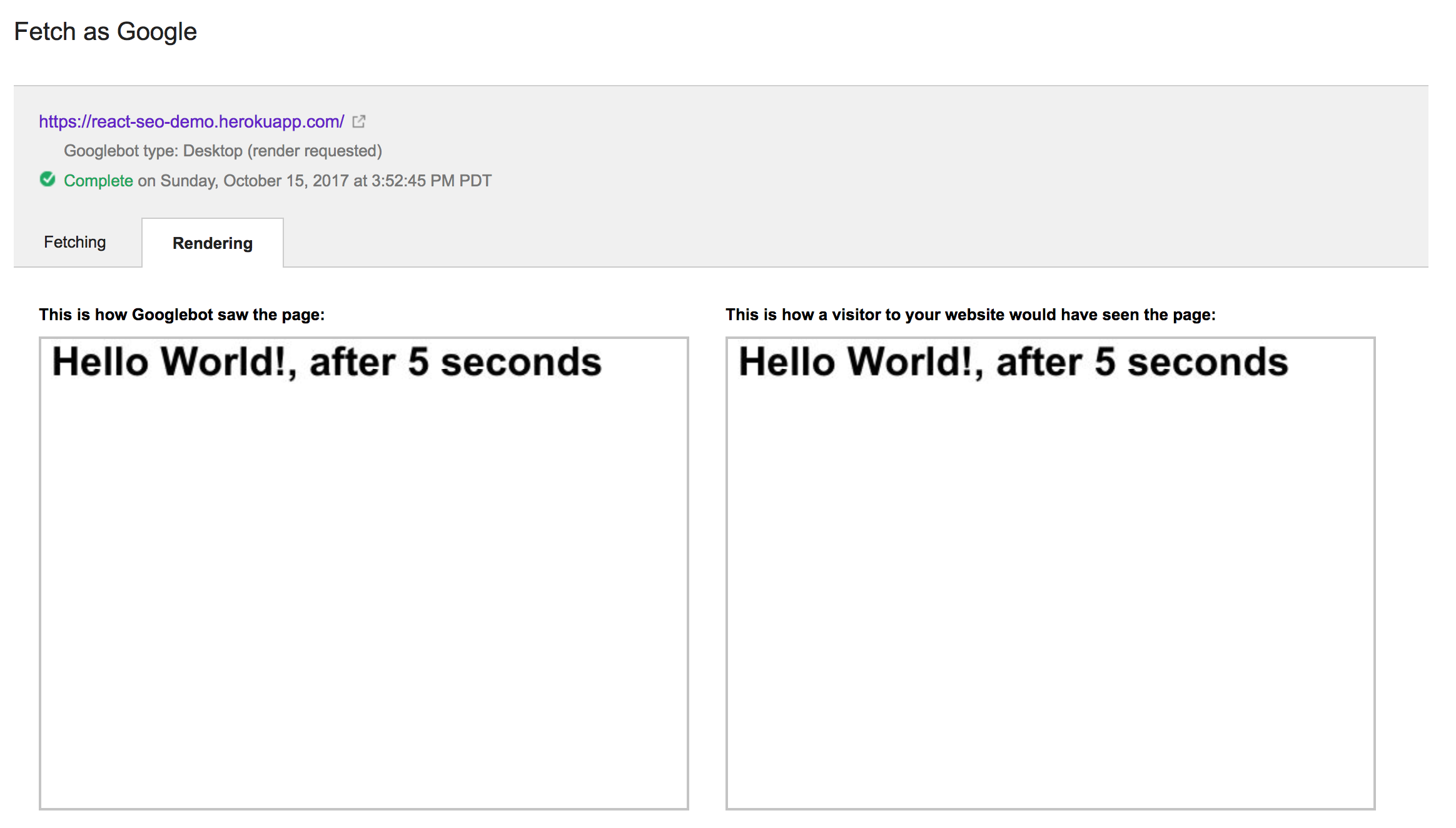
Interestingly, it was still able to see the output of the component. Additionally, the Fetch as Google operation took significantly less than five wall clock seconds to run, which makes me think that the browser environment it’s running in must be fast-forwarding through delays or something. Interestingly, if we increase five seconds to 15, we observe this output:
![]()
I have no idea how Google treats setTimeout. However, what the above test seems to indicate is that things that take too long to load will be ignored (not too surprising).
Now, let’s modify our component to call setInterval every second, and update a counter that we print to the screen:
class App extends React.Component {
constructor() {
super();
this.state = {
message: "",
count: 0
};
this.update = this.update.bind(this);
}
update() {
let count = this.state.count;
this.setState({ count: this.state.count + 1 });
}
componentDidMount() {
setInterval(this.update, 1000);
}
render() {
return (
<div>
<h1>{ `Count is ${this.state.count}` }</h1>
</div>
)
}
}This produces the following output:
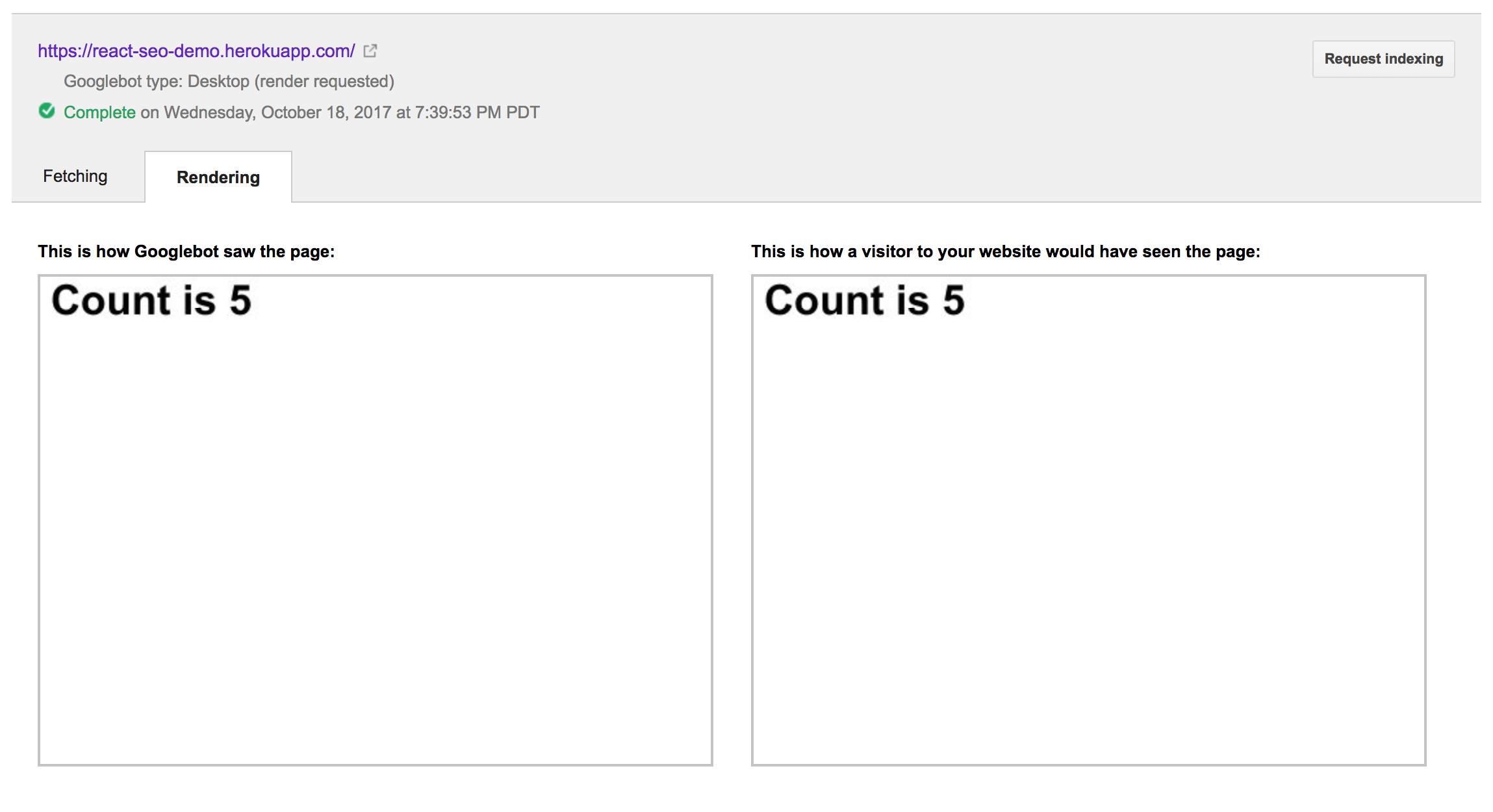
So, it captured the page render after waiting for five seconds. This aligns with the setTimeout behavior above. I’m not sure exactly how much we can deduce from these experiments; however, they do seem to confirm that the Googlebot will wait around for some small amount of time before saving the rendering of your website.
Summary
In my experience, Google is able to crawl React sites pretty effectively, even if they do have substantial data loads up front. However, it’s probably a good idea to optimize your React app to load the most important data (that you would want to get crawled) as quickly as possible when your app loads. This can mean ordering API calls a certain way, preferring to load partial data first, or even rendering the initial page on the server to allow it to load immediately in the client’s browser.
Beyond load times, there are several other things that can cause SEO problems for your React app. We’ve seen that missing polyfills may be problematic. I have also seen the use of arrow functions to be problematic, so it may be worth targeting an older ECMAScript version.
Great post! Thank you for sharing it.
My current system is also running on React. And also facing the SEO problem. After a long time to research and optimize, finally at Fetch as Google, Googlebot could see our site. But I’m also confusing that at Fetching tab, I didn’t the HTML DOM generated. I mean tag just included only. I wonder whether Googlebot had already indexed the content generated by Javascript or not?
Awesome, I really liked your post.
I’m thinking about doing my next side project using React and I was wondering about SEO.
Now I’m pretty sure that I can handle it, thank you very much.
This is what I wanted to know thanks. Seems like googlebot is getting smarter.
Thank U MATT NEDRICH….
Your post is really very helpful to me. But I have some queries. Please suggest.
After reading your post, I did the ‘Fetch as Google’ for two pages of my react SPA website and observed that the page content shown to user and the google bot are same. and I did indexed for those pages.
Now if I searched for my website, search results showing those two pages only. But the other pages are not showing in the google search results. why?
As you said, “fetch as Google” is a testing tool to test whether web page is really crawling by google search engine or not. Right?
I observed that, the pages that I tested in “fetch as Google” are indexed in google search engine, but the other pages are not getting indexed. Do I need to do “fetch as Google” tool option to all my urls in my website?
Please suggest…