Article summary
I have recently been implementing an Othello AI using the Monte Carlo Tree Search (MCTS) algorithm. One of the super cool things about MCTS (and actually the main reason I was attracted to it) is that you can use the same core algorithm for a whole class of games: Chess, Go, Othello, and almost any board game you can think of.
The main limitations are that the game has to have a finite number of possible moves in each state, as well as a finite length. Wikipedia tells me that all the top AIs for Go (a notoriously difficult game to make a good AI for) use some form of MCTS.
As the name hints, the algorithm works by representing all the possible states of the game in a “game tree.” The root node of the tree is the initial game state. For every valid move from a node (a game state), there is a child node representing the new game state if that move is chosen.
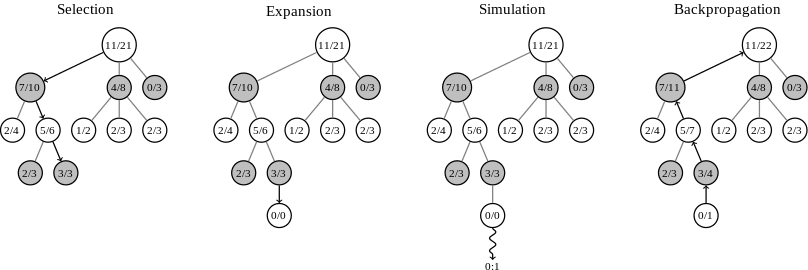
Then on top of this imaginary “game tree,” you build another more concrete tree that tracks some statistics (a visit count and a win count) generated with a four-step algorithm:
1. Selection
Walk down the game tree using a selection function at each node to determine which child node to walk to next. Stop when you reach a node that you don’t have statistics for yet.
The selection function most commonly used is called UCT and is as follows:
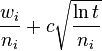
Where:
- wi stands for the number of wins after the ith move
- ni stands for the number of simulations after the ith move
- c is the exploration parameter. `sqrt(2)` is a good first guess for this number, but in practice, you’ll have to tune it experimentally.
- t stands for the total number of simulations, equal to the sum of all ni. Or, another way to think about this is that it’s the ni of the parent node
You then select the child node that the highest selection function value.
2. Expansion
Create a statistics node for the node you stopped at in the selection phase. It appears that most implementations will also force the expansion of all the children of a node once a node’s visit count reaches some threshold. One implementation I found used a threshold of 30.
3. Simulation
Simulate or roll out a game starting from the node you created in the expansion phase. You basically play a game to the end, choosing moves randomly (or semi-randomly). At the end, you keep track of which player won and then move to the backpropagation phase.
4. Backpropagation
Walk back up the tree to the root. On each statistics node, increment a “visit” count. Also, increment a “win” count if the current player of game node that’s the parent of the current game node is the player that won the simulation.
Then you repeat the four steps as many times as you can, until you’ve either decided you’ve done enough work or you run out of time. You pick the move that ends up at the child node with the win/visit count ratio.
And that’s it!
Thanks for the helpful post.
Is there any option to solve the problem of constructing a tree for state space has recurrent states. In this case, a rollout may lead a infinite recursion or a node representing same state may be found in many places in the tree.
Off-hand I don’t know of any applications of MCTS for game trees with cycles (graphs). I’ve only used it for finite games. I imagine it could be done, but it would require some modification to the core algorithm. At a minimum the simulation and back-propogation steps would need some re-work.
RE: Mehment
The way I’ve seen this handled is by having a hashing function that can create a unique id of any given position. A set of these hashes is then used to keep track of whether a position has already been visited.
If so, it is simply skipped (not added to the tree) and the next move for the parent position is used.
If not, the node is expanded as usual and the hash of the new position is added to the set.
This is FAIRLY efficient but it does introduce a major problem for a lot of games. Namely, generating a unique hash for a position. For something like chess or even go this is pretty doable. For an RTS with 5,000 agents running around, probably not.
One thing to mention is that MCTS is almost always used for very large tree spaces. And they are almost always time bounded. If you’re not going to time bound them, then you are probably better off with an Alpha/Beta search anyway.
So, bearing those two things in mind:
1) The likelyhood of repeated positions is low.
2) Even if that does happen, you’re going to quit after a fixed time anyway so at least you don’t have to worry about endless recursion. At worst, you will revisit the same position a bunch of times. At best, the UCB function will cause you to go to another node since it is designed to penalize frequently visited paths.