
Article summary
Navigating the HTML document object model (DOM) of a web app used to be one of the more tedious tasks of a front-end developer. With the increased usage of modern frameworks like Angular, however, this practice has become trivial over time. These frameworks provide an escape hatch from the DOM by encouraging component-based development.
Do you need to change the color of your navigation menu? It’s a component. Set the color in one file, and the whole app gets updated.
So, why do we still care? Sometimes client-side rendering is the only choice you have. If you’re using a cloud-based platform for your app like SharePoint Online (SPO), you don’t have much access to the server-side of things.
Even if you do, not all custom web apps are built with components in mind. You may have hundreds of custom pages stored somewhere that all need to be programmatically updated at once. Here are some easy ways to do that.
1. CSS Selectors
What is it?
Perhaps one of the first things that comes to mind, CSS selectors are a tried and true method of accessing elements in the DOM. This handy list of available CSS selectors will put you on the right track. A CSS selector can be many different things; it can be the class name of an element, the id, or the tag name.
How do I use it?
Let’s say you have a DOM structure like this:
<div class="container">
<a href="www.google.com">Click Me!</a>
<a href="www.bing.com">Click Me, Too!</a>
</div>If I wanted to select the div, I could either reference the element div or the class container. If I wanted to access the links, I could use a or div a or even href~=bing if I only wanted links that contain bing in the URL.
2. DOM Index
What is it?
The “DOM Index” refers to one’s ability to access children of an element like you would in an array. That means that if, on a given page, there is a container with n-size elements, I can iterate through them all or even access a specific one by its index/order. This relies heavily on the concept of nodes and parent/child relationships within the HTML DOM.
How do I use it?
Using the same DOM structure as in the example for #1, we can see that there are two links inside a div container. I can either iterate through them with a simple script or only grab the second one by doing something like document.getElementByTagName("div")[1].
3. XPath
What is it?
The true intention of using an XPath is to navigate through XML files. However, since the HTML DOM uses nodes to identify elements, it can be used here, too.
An XPath lets you access any element in one or more ways but can be less intuitive if you’re not familiar with the syntax. It’s unique in that, in a way, it has its own language for traversing the DOM. Try looking at this page of XPath selectors and their usages if you’re in a bind.
How do I find it and use it?
To select something simple like all the div elements on a page, "div" is the XPath. If you need to select the third div, you can try "//div[3]". But what if you need something more complicated? A modern browser like Google Chrome will let inspect elements and copy the XPath directly.
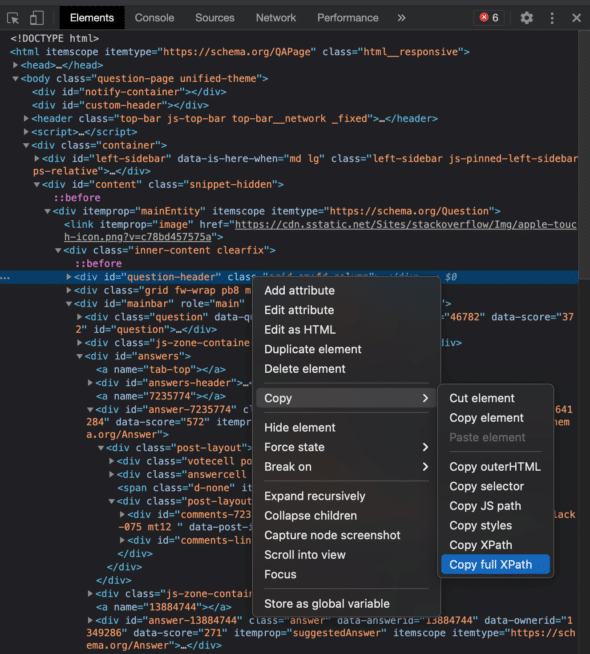
Not a lot of frameworks provide an out-of-box way of interpreting an XPath, but there’s probably a package you can install like this one from npm or the Nokogiri gem for Ruby.
When using components or accessing the server aren’t an option, these are handy ways to select HTML DOM elements.