Recently while working on the SME Toolkit, a project sponsored by the International Finance Corporation (a member of the World Bank Group), I encountered a problem with CDATA sections in XML documents.
CDATA sections are used in markup languages to identify general character data — data that should only be interpreted as characters, and not as specialized markup or commands. In XML, CDATA sections allow XML markup to be embedded, but not interpreted as part of the XML document itself.
For example, CDATA would allow XHTML to be embedded inside a larger XML document without treating the XHTML as part of the parent document:
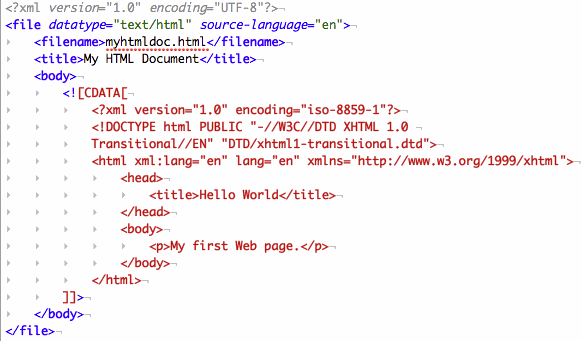
*Note: This XML document uses a contrived DTD for the purposes of example – these tags aren’t really part of the standard XML schema.
Unfortunately, there seems to be a great deal of confusion about the proper usage of CDATA sections. This is probably because they are not often worked with, and the CDATA markers behave differently than traditional XML tags. CDATA sections are defined as beginning with the following character sequence:<![CDATA[ …and ending with the first occurrence of the following character sequence: ]]>. Unfortunately, this means that CDATA sections cannot be ‘nested’ hierarchically like XML tags because any occurrence of the ending CDATA marker will terminate any open CDATA section.
This means that the following XML document is invalid because the first occurrence of “]]>” within the style section of the embedded XHTML document terminates the first CDATA section, leaving half of the embedded XHTML document to be considered as part of the larger XML document.
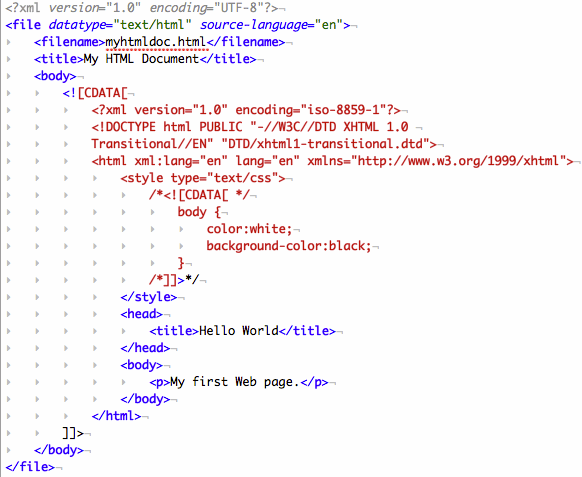
The preferred solution to this problem is to break-up the CDATA end markers when nesting them in a new XML document by inserting markers to close and re-open a CDATA section. Then, when the combined CDATA sections are interpreted, the original CDATA markers will be restored. This is accomplished by utilizing the following character sequence: ]] ]]> <
Essentially, while CDATA sections cannot be nested, it is possible to escape ending CDATA markers to prevent a CDATA section from being prematurely terminated during parsing. In the example above, parsing of the parent or container XML document will combine the two separate, yet adjacent, CDATA sections into a single set of general character data as intended, preserving the embedded CDATA markers. The nature of the embedded data will be preserved without having it mistakenly treated as part of the XML markup.
Further Reading:
The XML Standard, by the W3C:
Extensible Markup Language (XML) 1.0 (Fifth Edition) § 2.4 Character Data and Markup