
Recently, I worked on a project with a lot of complex data relationships. To abstract away some of this complexity, my team defined database views that summarized the information that matters to us. When building up those views in PostgreSQL, I found a couple of patterns particularly useful. I used conditional expressions (CASE and COALESCE) to determine counts or statuses for a group of rows and window functions to tack on aggregate calculation to every row. This post will dive into those useful expressions and functions.
Fake Marble Database
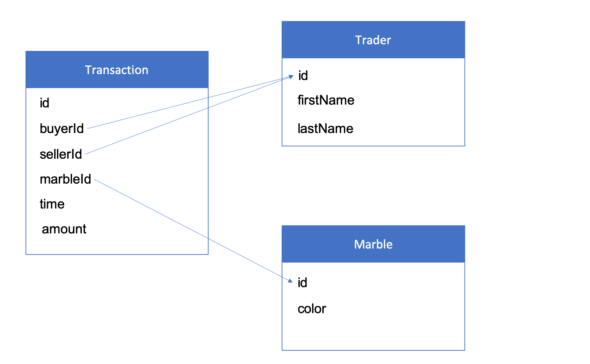
To demonstrate these patterns, I created a fake database with data about marbles, traders (who trade the marbles), and transactions (where a marble is sold from one trader to another). The database looks like this:
Using CASE WHEN to Create Queries
What is the count of transactions for each marble?
Say that I want to get a count of transactions for each marble. First, I’ll get all of the rows that represent a transaction for a marble. There may or may not be a transaction for a marble, so I’ll do a left join on the transaction table. If there are no transactions associated with the marble, “Transaction”.id will be null.
I’ll group the returned rows by the marble ID and then count how many rows there are in each group. If “Transaction”.id is null, it means there are no rows, so the count should be zero. If “Transaction”.id is not null, the count should increase by one.
Since I only want to increment the count when the transaction ID is not null, I will use the CASE conditional expression. This expression functions similar to an if/else statement. The syntax looks like this:
CASE
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
[WHEN ...]
[ELSE result_n]
END
On condition_1, returns result_1, on condition_2, returns result_2 etc.
For each group of marbles, the number is the sum of cases where “Transacton”.id is not null. Accordingly, I’ll return 1 if there is a transaction ID (adding 1 to “transactionCount”). To ignore the cases where “Transaction”.id is null, I’ll return 0 (adding 0 to “transactionCount”).
It looks like this:
SELECT
"Marble".id,
SUM(
CASE WHEN "Transaction".id IS NULL THEN
0
ELSE
1
END)::int AS transactionCount
FROM
"Marble"
LEFT JOIN "Transaction" ON "Transaction"."marbleId" = "Marble".id
GROUP BY
"Marble".id;
What is the status (traded/never traded) for each marble?
Let’s say a marble has a status of “traded” if there are any transactions associated with it. Otherwise, its status is “never traded.” If the count of transactions is bigger than 0, the marble is “traded.” Otherwise, it is “never traded.” The traded status can also be evaluated with a CASE expression.
Using the case statement from the previous example, we get the transaction count–but this time, it will be wrapped with another case statement. That “wrapper” case statement will use the transaction count to determine the marble status:
SELECT
"Marble".id,
(
CASE WHEN (SUM(
CASE WHEN "Transaction".id IS NULL THEN
0
ELSE
1
END)::int) > 0 THEN
'traded'
ELSE
'neverTraded'
END)::text AS status
FROM
"Marble"
LEFT JOIN "Transaction" ON "Transaction"."marbleId" = "Marble".id
GROUP BY
"Marble".id;
If we were to create a view using this SELECT, we could easily get the status for any marble ID by querying that view.
How much money (in total) has been traded on a particular marble?
What if, instead of summing up the number of transactions, I wanted to sum up the total amount spent on transactions? Instead of adding 1 when “Transaction”.id is not null, I would add “Transaction”.amount when “Transaction”.amount is not null (or “Transaction”.id is not null–either will work).
SELECT
"Marble".id,
SUM(
CASE WHEN ("Transaction".amount IS NULL) THEN
0
ELSE
"Transaction".amount
END)::decimal AS totalTraded
FROM
"Marble"
LEFT JOIN "Transaction" ON "Transaction"."marbleId" = "Marble".id
GROUP BY
"Marble".id;
Using COALESCE to Create Queries
Round 2: How much money (in total) has been traded on a particular marble?
Using a case statement to get the total traded amount can get a bit complicated. Basically, if “Transaction”.amount isn’t null, we want to add “Transaction”.amount; otherwise, we want to add zero. COALESCE is great for providing a default value for the null case in a more succinct way.
COALESCE takes any number of arguments and returns the first argument that is not null. I’ll make “Transaction”.amount the first argument and zero the second argument. If there is no “Transaction”.amount to add, the default (0) will be added.
SELECT
"Marble".id,
SUM(COALESCE("Transaction".amount, 0))::decimal AS totalTraded
FROM
"Marble"
LEFT JOIN "Transaction" ON "Transaction"."marbleId" = "Marble".id
GROUP BY
"Marble".id;
This approach applies the same logic. It’s just a little shorter!
Using WINDOW to Create Queries
For each transaction, how does the transaction amount compare to other transactions of the same color?
For each transaction row, I want a column that gives me the average transaction cost for the color. Let’s say that blue marbles cost more than green marbles. I could see, for example, a particular transaction for a blue marble compared to the average transaction cost for all blue marbles.
This means that the number of rows returned should not be reduced when computing the average transaction cost per color. I could GROUP BY color and compute the average for each group of marbles. However, GROUP BY only returns as many rows as there are groups. To return all the rows using GROUP BY, there would need to be a self-join with the results of the GROUP BY.
A window function, unlike an aggregate function, does not reduce the number of rows returned.
A window function, in its most basic form, has the name of the window function (e.g. avg), the arguments of the window function (e.g. “Transaction”.amount), and an OVER clause. There is optionally a PARTITION BY that specifies how to partition up the rows. The window function is applied to each of these partitions.
In this case, I want to partition the rows by the color of the marble. The partition function of avg with argument “Transaction”.amount is applied to each group of rows. Each marble row will then contain the average transaction cost for marbles of the same color.
SELECT
"Transaction".id,
"Marble".color,
"Transaction".amount,
avg("Transaction".amount) OVER (PARTITION BY "Marble".color) AS "averageTransactionForColor"
FROM
"Transaction"
JOIN "Marble" ON "Marble".id = "Transaction"."marbleId";
Let’s say I want not just the average transaction amount, but also the minimum and maximum transaction amount for all marbles with the same color. One option would be to have multiple window functions with their own PARTITION BY, but that would be an unnecessary duplication. Instead, I could create a WINDOW clause and then reference that window clause in each window function.
SELECT
"Transaction".id,
"Marble".color,
"Transaction".amount,
avg("Transaction".amount) OVER w,
min("Transaction".amount) OVER w,
max("Transaction".amount) OVER w
FROM
"Transaction"
JOIN "Marble" ON "Marble".id = "Transaction".marble
WINDOW w AS (PARTITION BY "Transaction".marble);
I can now see how the transaction amount for a given marble compares to the minimum, maximum, and average transaction amount for marbles of the same color. Each row still has its separate identity, but it has been enhanced with aggregated values.
The CASE and COALESCE conditionals, as well as the window functions, were great tools for creating the views that we needed. Having views that summarized and aggregated our data meant that we could easily query for what we needed.