
Article summary
Over the past year, I’ve been working with GraphQL to build APIs. GraphQL is a query language that allows for flexible endpoints for servers, giving consumers the power to control what data they are receiving.
GraphQL is an alternative to REST APIs, which tend to be rigid about the data a consumer can receive. When requesting data from a REST API, the consumer has access to a restricted set of data, usually related to a single model.
However, GraphQL does not restrict the user to a restricted set of data. With GraphQL, a consumer can walk across a graph of related models and retrieve a complete and cohesive data set (hence the name “Graph”-QL).
To demonstrate this graph-traversal concept, I created a family tree application. The data model for a family tree is simple, consisting of people related to other people. Designing an API with GraphQL allows this application to have a clean and powerful interface for exploring this data set.
For my next few posts, I plan on building up this application and exploring the interesting software design concepts that GraphQL enables. In this post, I’ll demonstrate the foundational pieces of an Express server implementing GraphQL. This simple server consists of a single endpoint that will allow a consumer to walk a tree of related people. You can check out my project from GitHub if you’d like to follow along.
The Application Architecture
My GraphQL server consists of three main layers: the schema layer, the resolver layer, and the data layer. For this example, each layer is fairly thin, so I’ll give a brief overview of them. I’ll skip over the finer details of the Express server and focus on the broader ideas found in this application.
To build this application, I used the Apollo Framework, which one of my colleagues wrote about in more detail here. Check it out if you’re interested.
The schema layer
The schema layer defines the API of our GraphQL server, controlling what queries a client can make, as well as the types for the data model. For a family tree, the schema is very simple:
type Person {
id: Int
firstName: String
lastName: String
parents: [Person]
children: [Person]
}
type Query {
getPeople: [Person]
getPerson(id: Int!): Person
}
schema {
query: Query
}
This schema consists of a single type and two queries. The Person type defines what data is used to describe a person. A Person has a database ID, a first and last name, and parents and children–each of which are lists of other Persons.
There are two queries: getPeople and getPerson. getPeople returns a list of all Persons in the system. getPerson can fetch a single Person given a database ID.
The resolver layer
The resolver maps data from various sources to our schema:
{
Person: {
parents(person, args, context) {
return context.Person.findParents(person.id);
},
children(person, args, context) {
return context.Person.findChildren(person.id);
},
},
Query: {
getPeople(root, args, context) {
return context.Person.findAll();
},
getPerson(root, args, context) {
return context.Person.findById(args.id);
},
},
}
getPeople and getPerson queries call into the data layer to retrieve Person-related information. The ID, first name, and last name are implicitly resolved since they are simple types, but the parent and children fields have to retrieve more Person data from the data layer.
The Person resolver maps the data to the individual fields. The id, firstName, and lastName are implicitly resolved, so we just have to defined how to resolve parents and children.
The data layer
To feed data into the resolvers, I created a Person class that handled the database interactions. (This class can be found in server/models/models.ts of the example project.) Resolvers can interact with the database that holds the family tree data through this interface.
The database has a simple structure, consisting of two tables. One table is the persons table, which holds the information about a person. The second table is a parental_relationships table, which has a child_id and parent_id, each of which references persons. With these two tables, we can build out a simple family tree.
Exploring the Data with GraphQL
With this basic infrastructure in place, we can start writing GraphQL queries and explore some of these relationships.
First, let’s find all of the people in the system:

This data doesn’t tell us how these people are related, but we can begin to explore this family tree by starting with a single person. Let’s focus on Mary and see who her parents and children are:
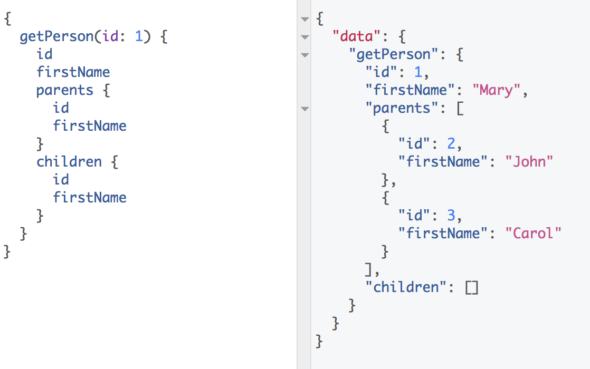
We can continue to walk the family tree and see who Mary’s grandparents are:

By walking both up and down the tree, we can find siblings of Mary:

Or even cousins:

With this very simple GraphQL implementation, we can build fairly complex queries to answer questions about this particular family tree. With a typical REST API, we probably would have had to have a different endpoint for each of these queries.
In my next post, I’m planning on expanding the schema with improved resolvers to leave out redundant results (such as Mary being one of Mary’s siblings). Also, I’ll demonstrate how we can improve the performance of these queries by preventing N+1 issues.
Until then, check out the project for yourself and create your own GraphQL queries.