
A couple of weeks after I worked on PDF snapshot testing with Node and GraphicsMagick, I was tasked with writing some code to generate downloadable Microsoft Excel Workbook files. I thought I would use snapshot comparisons again, much as I did with PDF files to automatically detect regressions in the implementation.
Instead of sticking with the visual approach I used for PDF snapshot testing, I thought I would deconstruct the Excel Workbook file and display the diffs of the individual files within it. These files are stored as XML, but when formatted a bit, they are readable enough for the human eye.
Setup
I used a few Node modules to simplify the code. To install these Node modules on a Mac, we can use:
yarn add adm-zip lodash diff xml-formatter colorsCode
First, we’ll define the paths that we’ll use to store our expected and actual Excel files. The Excel Workbook files are stored in a sub-directory (__xlsx-snapshots) so that they will be close to our test code and easy to find.
const reportPath = path.join(__dirname, '__xlsx-snapshots');
const actualFileName = path.join(reportPath, 'actual.xlsx');
const expectedFileName = path.join(reportPath, 'expected.xlsx');Next, we’ll define a simple function to fetch the Excel Workbook file from our server. In our case, we generate the Excel Workbook on the fly (using js-xlsx) and send it to the client.
const getExcelWorkbook = async (id: number) => {
const workbookUrl = `https://localhost:3100/workbook/${id}`;
await download(workbookUrl, actualFileName);
};Then, we’ll define a function to compare our newly generated (actual) Excel Workbook against our expected Excel Workbook. We will be uncompressing the Excel Workbook file (which is actually a set of XML files in a ZIP archive), then reading each file and comparing them one by one. When a particular file doesn’t match, we’ll format the XML nicely and output them in a color-coded fashion.
export const isExcelEqual = (aFilePath: string, bFilePath: string) => {
const archiveA = getZipAsArchive(aFilePath);
const archiveB = getZipAsArchive(bFilePath);
const mismatches = compareArchives(archiveA, archiveB);
if (mismatches.length > 0) {
for (const mismatch of mismatches) {
const results = diff.diffLines(archiveA[mismatch.filePath], archiveB[mismatch.filePath]);
console.info('-------------------------------------------------------------------------------');
console.info(`${mismatch.filePath}:`);
console.info('-------------------------------------------------------------------------------');
for (const result of results) {
console.info(trimEnd(colorFormat(result)));
}
console.info('-------------------------------------------------------------------------------');
console.info();
}
}
return mismatches.length === 0;
};Next, we’ll import some useful Node modules.
import * as AdmZip from 'adm-zip';
import * as _ from 'lodash';
import * as diff from 'diff';
const xmlFormat = require('xml-formatter');
const colors = require('colors');
// set up some reasonable colors
colors.setTheme({
filePath: 'grey',
unchanged: 'grey',
added: 'red',
removed: 'green',
});Then, we’ll define a simple function to read a ZIP file and populate the contents of an object with the XML files as strings.
interface IndexedArchive {
[k: string]: string;
}
const getZipAsArchive = (filePath: string): IndexedArchive => {
const zip = new AdmZip(filePath);
const entries = zip.getEntries();
return entries.reduce((indexArchive, entry) => {
indexArchive[entry.entryName] = xmlFormat(entry.getData().toString('utf-8'));
return indexArchive;
}, {} as IndexedArchive);
};At this point, we can define a function to compare the contents of the two archives.
const compareArchives = (archiveA: IndexedArchive, archiveB: IndexedArchive) => {
const allFilePaths = _.uniq(Object.keys(archiveA).concat(Object.keys(archiveB)));
const comparison = allFilePaths.map((filePath) => {
return {
filePath,
matches: archiveA[filePath] === archiveB[filePath],
};
});
return comparison.filter((compare) => !compare.matches);
};Finally, we’ll define a few functions to nicely format the differences for humans to read.
const colorFormat = (result: diff.IDiffResult): string => {
const value = result.value;
if (result.added) {
return colors.added(formattedLine(value, '-'));
}
if (result.removed) {
return colors.removed(formattedLine(value, '+'));
}
return colors.unchanged(formattedLine(value, ' '));
};
const formattedLine = (line: string, prefix: string): string => addLinePrefix(line, prefix);
const addLinePrefix = (line: string, prefix: string): string => {
return trimEnd(line)
.split(/(\r\n|\n|\r)/)
.filter((segment) => segment.trim().length > 0)
.map((segment) => `${prefix} ${trimEnd(segment)}`)
.join('\n');
};
const trimEnd = (text: string) => {
return text.replace(/[\s\uFEFF\xA0]+$/g, '');
};Now, we’ll define a snapshot function which operates as follows:
- When the expected Excel Workbook file does not exist, will simply copy the actual Excel Workbook onto the expected Excel Workbook and pass the test.
- When the expected Excel Workbook file does exist, we will compare it against the actual Excel Workbook and issue an error if they do not match.
When the expected and actual Excel Workbook do not match, we can do a manual inspection. When we are satisfied, we can rerun the test with the UPDATE environment variable set. This will overwrite the expected Excel Workbook with the actual Excel Workbook and pass the test.
export const snapshot = async (actualFilePath: string, expectedFilePath: string, comparisonFilePath: string) => {
if (process.env.UPDATE || !(await exists(expectedFilePath))) {
await copyFile(actualFilePath, expectedFilePath);
} else {
const helpText = [
'',
'-------------------------------------------------------',
`Actual contents of Excel workbook did not match expected contents.`,
`Expected: ${expectedFilePath}`,
`Actual: ${actualFilePath}`,
`Comparison: ${comparisonFilePath}`,
'-------------------------------------------------------',
'',
].join('\n');
const isDocumentEqual = await isExcelEqual(expectedFilePath, actualFilePath);
if (!isDocumentEqual) {
console.error(helpText);
}
return expect(isDocumentEqual, 'Documents are not equal').to.be.true;
}
};Finally, we’ll write a simple test which exercises this method.
describe('Excel Workbooks', () => {
it('can generate an Excel Workbook', async () => {
// generate test data
const order = generateTestOrder();
// fetch actual pdf
await getExcelWorkbook(order.id);
// compare snapshot of actual and expected Excel Workbooks.
await snapshot();
});
});Execution
First, we’ll run the test.
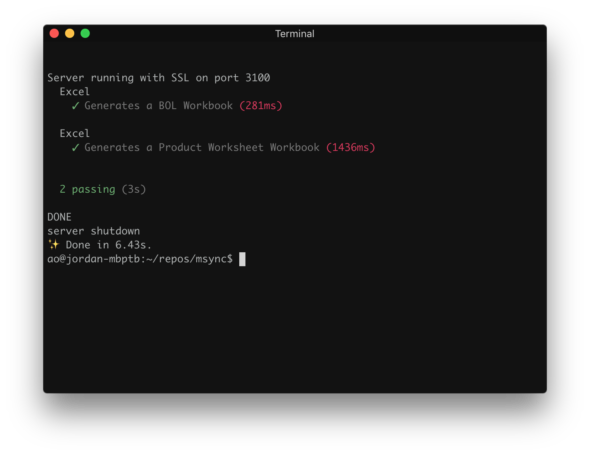
We can see that both the actual and expected Excel Workbooks have the same timestamp.
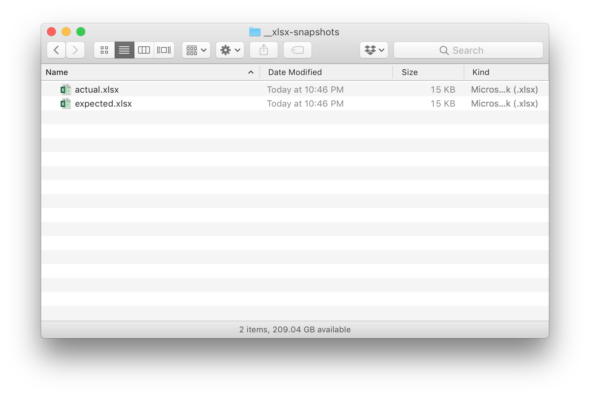
Next, we’ll run our test again to see that only the actual Excel Workbook has been updated.
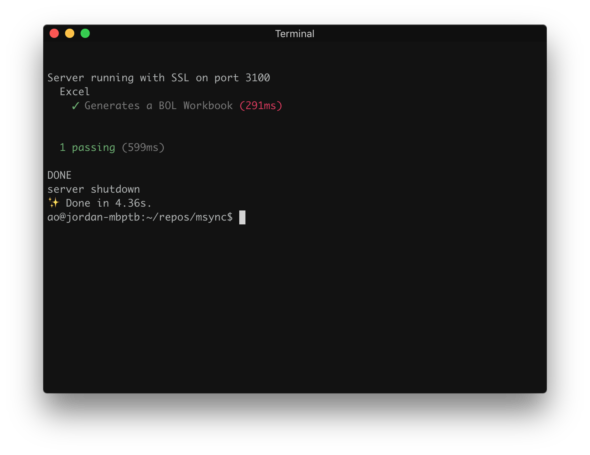
We can see that the timestamp for the actual Excel Workbook has changed, but the expected Excel Workbook hasn’t.
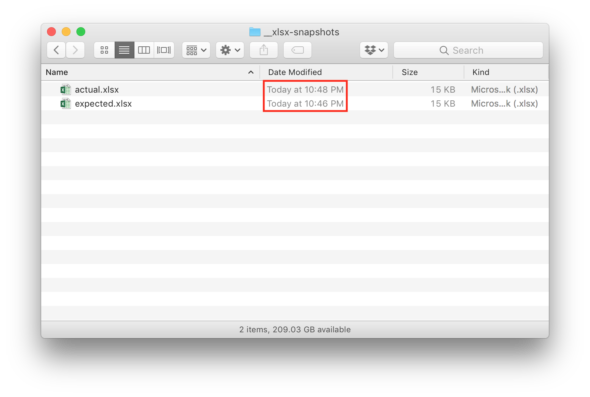
Then, we’ll modify our implementation and re-run our test.
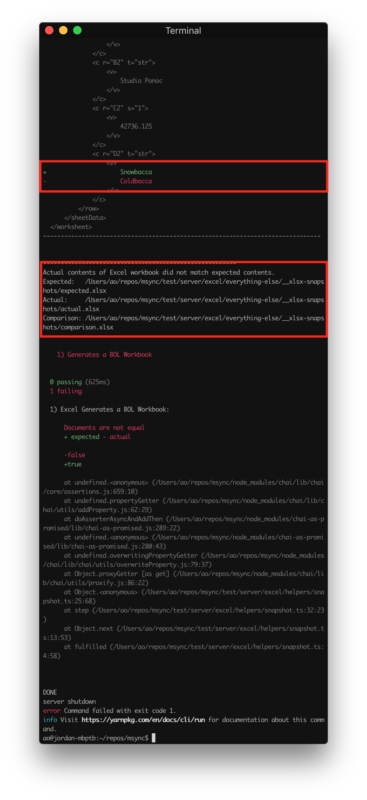
We can see that our test detected a change between the actual and expected Excel Workbooks and reported it as a test failure.
At this point, we will will manually inspect the expected Excel Workbook and actual Excel Workbooks to perform a visual comparison of the two.
If, after manually inspecting the expected and actual Excel Workbooks, we find that these changes are acceptable, we can simply re-run our test with the UPDATE environment variable set.
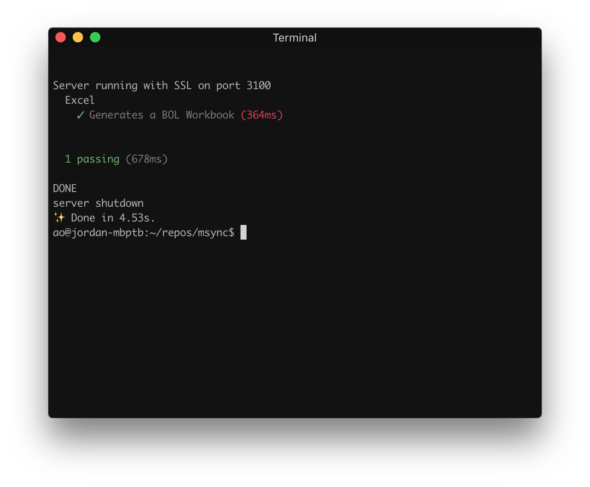
Finally, we can see that the timestamp of the expected Excel Workbook is updated.
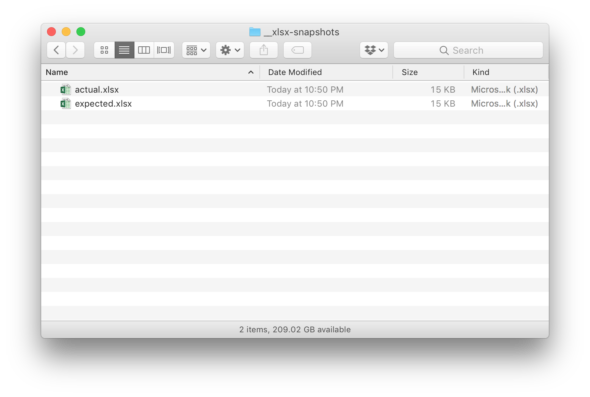
We can add this new expected Excel Workbook to our repo and commit. If we are using a continuous integration environment, we will automatically see a test failure when the actual output differs from the expected output.