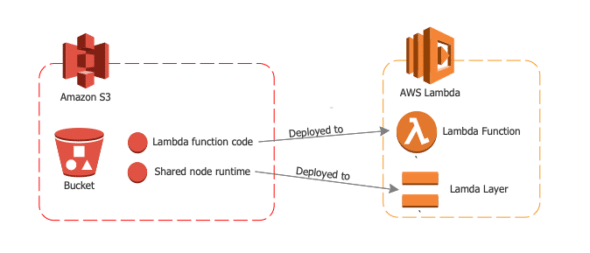
For my project, we have a Node.js server deployed as an AWS Lambda function. The server’s dependencies (Node modules) are deployed in a Lambda layer. We want an easy process to deploy a new Lambda layer version when we update the Node modules and to update the Lambda function code whenever we update the local server files.
The deployed Lambda gets its function code from an S3 bucket with a zip of bundled server code. The Lambda layer also gets its dependencies from a zip in the S3 bucket. Here is a diagram of our deployed infrastructure:
1. Create a Makefile
We want to be able to update our deployed code whenever any of our dependencies or source code change. Make is a great fit for this—it lets us describe tasks that should be run or files that should be updated whenever other files change.
In order to use make, you must first create a makefile describing the relationship between different files in your project. Once set up, running make in the command line will perform all necessary updates to the files in your project.
These updates are determined by the makefile rules, which specify how and when to remake target files or trigger an action.
The syntax of a rule looks like:
[TARGET] : [PREREQUISITES]
[RECIPE]
Target: Name of file/executable/action generated by a program
Prerequisite: File used to create the target
Recipe: Usually serves to create target files whenever any of the prerequisites change (but does not necessarily need to have prerequisites)
You can learn more about makefiles here.
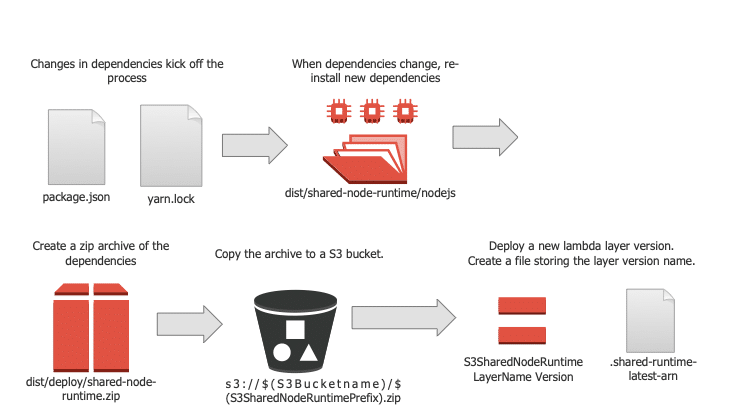
2. Publish a New Layer Version when Dependencies Change
Whenever the dependencies change, we want to publish a new Lambda layer version with the updated dependencies.
Install dependencies
Our server is a Node server with a package.json and yarn.lock file specifying all of its dependencies.
So, whenever the package.json or yarn.lock changes, we want to re-install the dependencies into a folder containing our Node modules (we put them in dist/shared-node-runtime/nodejs).
To install the Node modules into the Node.js directory, we will:
- Copy the package.json file into the Node.js directory
- Navigate to the Node.js directory
- Install the Node modules
- Delete the package.json file
We want to run these commands sequentially. By default, make will run all of the instructions in the recipe at the same time. To run them sequentially instead, each instruction needs a ; \ at the end of the line.
The following command installs the updated packages into the Node modules folder whenever the required packages specified by package.json/yarn.lock change.
dist/shared-node-runtime/nodejs/node_modules: package.json yarn.lock
cp package.json yarn.lock dist/shared-node-runtime/nodejs/; \
cd dist/shared-node-runtime/nodejs; \
yarn install --production=true; \
rm package.json yarn.lock
Create a ZIP archive
When publishing a new layered version, the content must be in the form of a ZIP archive. Right now, we have no ZIP archive, just a bunch of Node modules in a folder.
The following command creates a new ZIP file whenever any of the Node modules change. Because we want to run this command when Node modules update, the prerequisite is the Node modules folder.
dist/deploy/shared-node-runtime.zip: dist/shared-node-runtime/nodejs/node_modules
cd dist/shared-node-runtime; \
zip -Xr ../deploy/shared-node-runtime.zip *
Upload the files to S3, then publish the new layer version
Next, we need to get the updated ZIP archive deployed. To deploy, we:
- Copy the zip to an S3 bucket. We used the Amazon CLI s3 copy command to copy our local shared Node modules archive to the S3 bucket. The copy command takes the name of the file to copy as its first argument and the location to copy the file to as its second argument.
- Deploy a new AWS layer version with the updated dependencies and save the layer version name. The AWS CLI publish layer version command creates a Lambda layer from the ZIP archive. When calling it, we provide the name of the bucket containing ZIP archive and the S3 bucket key (which we made to be the name of the ZIP archive).
Calling publish layer version with a layer name will create a new layer version for that layer. We’ll want to save the layer version name to use when deploying the actual Lambda.
How do we get and save the deployed layer version name? The publish layer command outputs a JSON structure that contains the key LayerVersionArn. So, we can pipe the output of the publish command and then use jq (a command-line JSON parser) to key the value of LayerVersionARN. We then save that to the target file to use when deploying the Lambdas.
We don’t need to type out the name of the target file in the make instructions. In make files, $@ is equivalent to the full name of the target for the recipe, so we use $@ in place of the name of the target file, like this:
| jq ‘.LayerVersionArn’ > $@Since we want to publish to S3 and publish a layer version whenever the ZIP archive changes, the ZIP archive is the prerequisite in the make recipe.
.shared-runtime-latest-arn: dist/deploy/shared-node-runtime.zip
aws s3 cp $< "s3://$(S3Bucketname)/$(S3SharedNodeRuntimePrefix).zip" \
aws lambda publish-layer-version \
--layer-name "$()" \
--content "S3Bucket=$(S3BucketName),S3Key=$(S3SharedNodeRuntimePrefix).zip" \
--description "Shared Node.js runtime" \
--compatible-runtimes nodejs10.x \
| jq '.LayerVersionArn' > $@;
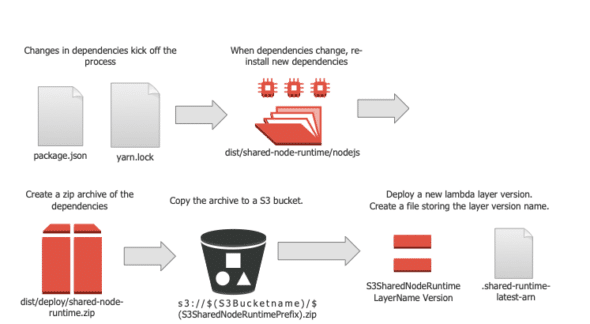
Summary
So far, the process to upload Node modules to a Lambda layer looks like this:
3. Update Lambda Function on Code or Dependency Updates
At this point, we’ve deployed the Lambda dependencies to a Lambda layer and saved the latest Lambda layer name.
Next, we want to deploy the Lambda whenever its source files change. To keep things simple, let’s say our server is made up of one TypeScript source file named lambda.ts.
Build the server on code change
To convert the TypeScript file into the JavaScript bundle, we call our yarn build:server command. Under the hood, this command just uses webpack to compile the TypeScript files into a JavaScript bundle. This outputs the JavaScript bundle (the lambda.js file) into the current directory.
We want to save the lambda.js file in an easily accessible place, so we set our target to dist/lambda/lambda.js.
dist/lambda/lambda.js: package.json yarn.lock modules/server/lambda.ts
yarn build:server
Zip up the changed Lambda
Actually updating the Lambda function’s code to use this bundle requires the JavaScript bundle to be in the form of a ZIP archive. We can compress the JavaScript bundle into a ZIP whenever the JavaScript bundle changes.
In make, $@ is equivalent to the name of the target file and $< is equivalent to the name of the first prerequisite being built. So zip -xJ $@ $< means produce an archive with the name of the target file ($@) that takes an input file with the name of the first prerequisite ($<).
We use that instruction in the recipe to create the ZIP:
dist/deploy/lambda/lambda.zip: dist/lambda/lambda.js
zip -Xj $@ $<
Upload the Lambda
Whenever the Lambda ZIP archive updates, we want to copy the updated ZIP to our S3 bucket. We used the AWS S3 copy command to copy the Lambda archive to the specified S3 bucket. The Lambda archive is the first prerequisite, so it is represented by $<.
After we finish uploading the Lambda, we want to trigger a Lambda deploy. We can generate a target file which can be a prerequisite for the deployment step, triggering a Lambda re-deploy on update.
Whenever we have a dist/deploy/lambda/lambda.zip file, we want to create that target file. Let’s call it lambda-uploaded. Since the target file shares part of its name with the prerequisite file, we can substitute the shared part of the name with a wildcard, like this:
target%: prereq%.zipWhenever prereqX is made, the target will be targetX.zip. In our case, since the target file is .%-uploaded, if % is Lambda, the target file will be .lambda-uploaded. We can use touch to create the .lambda-uploaded file uploading to S3.
.%-uploaded: dist/deploy/lambda/%.zip
aws s3 cp $< "$(S3BucketName)$(S3BucketKeyPrefix).zip" \
touch $@
Deploy the Lambda
If there is new function code for the Lambda or a new Lambda version is deployed, we want to publish the new Lambda code and update the AWS function configuration to use the new Lambda version. The prerequisite files to updating the Lambda function code are:
- .lambda-uploaded, which is updated whenever the Lambda bundle ZIP archive in the S3 bucket is updated.
- .shared-runtime-latest-arn, which is updated whenever a new Lambda layer version is deployed.
We used AWS Lambda CLI commands to actually update the Lambda function code and configuration like this:
.%-deployed: .%-uploaded .shared-runtime-latest-arn
aws lambda \
update-function-code \
--function-name $(LamdaFunctionName) \
--s3-bucket $(S3BucketName) \
--s3-key $(S3SharedNodeRuntimePrefix).zip" \
aws lambda \
update-function-configuration \
--function-name $(LamdaFunctionName) \
--layers $(shell cat .shared-runtime-latest-arn)
Our Lambda function should now be updated with the new code and configured to use the new dependencies.