Article summary
As blogged about previously, the SME Toolkit has a feature which allows integration with telephone companies to send SMS messages via the SMPP protocol.
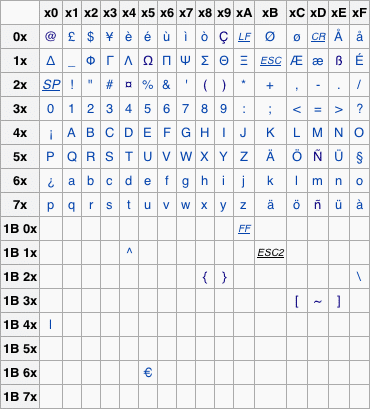
Recently, we experienced the challenge of needing to communicate SMS messages to a telco utilizing the 7-bit GSM Default Alphabet. The challenge arose from the fact that, internally, the SME Toolkit uses the UTF-8 encoding scheme, and we were trying to communicate Portuguese language messages.
The Portuguese language utilizes characters which are not represented in the 7-bit GSM Default Alphabet, yet GSM-7 was the only way we could communicate SMS messages to the telephone company. The challenge was to send Portuguese language SMS messages from the SME Toolkit to end-user mobile handsets via the telephone company without rendering the SMS message unreadable.
The Problem
We could not very well just ask people to not send Portuguese-language specific characters which did not exist in GSM-7 — that would be tacky and very user-unfriendly. We could not use other encodings which did support the Portuguese language, such as UCS-2/UTF-16 as the telephone company did not support them. Finally, we could not use one of the newer features of GSM, national language shift tables, as the telephone company did not support them either.
Doing a standard conversion to from UTF-8 to GSM-7 would be ‘lossy’ in that the characters which did not exist in GSM-7, but did exist in UTF-8 could not be represented. A replacement character would be used to indicate that no valid character existed in the GSM-7 encoding to represent the given UTF-8 character.
The Solution
After some discussion with target Portuguese speakers who had mobile handsets with the telephone company, we discovered that it was acceptable to use a close replacement character for the Portuguese-language specific characters which the telco did not support.
For example, for the purposes of SMS messages, it was acceptable to replace ‘á‘ with ‘a‘, ‘ó‘ with ‘o‘, and ‘ã‘ with ‘a‘. A SMS message such as ‘PME Negócios‘ could be displayed as ‘PME Negocios‘ without rendering the message unintelligible.
This was a much better alternative than a ‘lossy’ conversion from UTF-8 to GSM-7 which would likely result in the replacement character ‘?‘ being used for the Portuguese-language characters which did not exist in GSM-7. For instance, ‘PME Negócios‘ would become ‘PME Neg?cios‘. While not ideal, using a close replacement character is clearly much preferable to using just a question mark.
But how to achieve this conversion? Very few resources exist to convert UTF-8 to GSM-7, much less do so with the sort of flexibility we had in mind. Normally, I would opt to use something like iconv to convert between encodings, but iconv does not natively support GSM-7.
The Implementation
In the end, I decided to write a custom library to handle conversion from UTF-8 to GSM-7, which would allow for replacement characters which were as close as possible to the original UTF-8 character. This was achieved through direct 1-to-1 conversion of GSM-7 supported characters, and then transliteration to handle the remainder.
The library takes a UTF-8 string, and examines each character separately. If the character has a GSM-7 equivalent, the GSM-7 value of that character is provided using a mapping. If the character does not have a GSM-7 equivalent, it is transliterated to ASCII. (ASCII is fully represented by GSM-7.) Once the UTF-8 character has been transliterated to ASCII, the GSM-7 value of that ASCII character is provided using a mapping.
In this way, a UTF-8 string can be converted to GSM-7, using the best possible replacement character instead of simply dropping the character altogether, or using a generic replacement. If, for some reason, there is no way to transliterate a UTF-8 character to ASCII, then a replacement character must be used as there is no alternative. While definitely not ideal, this solution was sufficient for our needs.
For instance, with the UTF-8 string Seqüência de teste em Português, there are many characters which can be directly converted to GSM-7 without any issue, but a few which need to be handled specially. Let’s go through the logic.
- The characters:
a, c, d, e, g, i, m, n, o, P, q, r, S, s, t, u
All have direct mappings to GSM-7 (which, conveniently, have the same hex value as in UTF-8) - ‘
ü‘ does exist in GSM-7, and has a value of0x7E. So that’s easy, we provide that hex value for the conversion. - ‘
ê‘ does not exist in GSM-7. So… we transliterate to ASCII, which would give ‘e‘. - ‘
e‘ does exist in GSM-7, and has a value of0x65. So, we provide that hex value.
We now have a string which, if rendered in GSM-7, would look like ‘Seqüencia de teste em Portugues‘. The actual hex value in GSM-7 would be:
\x53\x65\x71\x7e\x65\x6e\x63\x69\x61\x20\x64\x65\x20\x74\x65\x73\x74\x65\x20\x65\x6d\x20\x50\x6f\x72\x74\x75\x67\x75\x65\x73
Conclusion
This strategy for converting a UTF-8 string to the 7-bit GSM Default Alphabet allowed us to communicate with the telephone company utilizing the required encoding, but without fully sacrificing the ability to send meaningful messages in Portuguese. It certainly isn’t as optimal as sending messages encoded as UTF-8 or UCS-2/UTF-16, but it suffices when no other option is available.
[…] posted here: Converting UTF-8 to the 7-bit GSM Default Alphabet | Atomic Spin Share this: Tag Search: negócios Comments: Leave a […]
I believe that using a Ruby library like Unidecode to handle the transliteration would solve your problems almost instantly (I use it to generate almost “perfect” slugs for all known languages in my ruby_extensions library).
Good suggestion, Paweł. Yes, the the Unidecode library is definitely one that I considered for transliteration support. In the end, I ended up settling on Unidecoder. While transliteration is a necessary component of the strategy I outlined, a transliteration library alone does not suffice as it will not handle converting the transliterated characters (usually ASCII) to GSM-7. While ASCII characters are fully represented in GSM-7, many have different values.
Sorry for my bad English if possible a reply in Spanish!
Hello I’m from Costa Rica currently working on an MVO, we have a serious problem with android terminal and simbian anna which do not receive SMS. I found that are UTF-8 at least my xperia x8 .. The error is sm-EnumeratedDeliveryFailureCause: equipmentProtocolError (1)
known as SMS are sent in 7-bit GSM Default Alphabet, analyzing this information, this is a possible cause?. Anyone know if this is related?? Help please ..
Buenas Soy de Costa Rica actualmente trabajo en un MVO, tenemos un problema serio con terminales android y simbian anna los cuales no reciben SMS nuestros he visto por hay que tiene codificación UTF-8 al menos mi xperia x8.. El error que tenemos es sm-EnumeratedDeliveryFailureCause: equipmentProtocolError (1)
como se sabe los SMS se envían en 7-bit GSM Default Alphabet, analizando lo visto acá creo que esta sea una posible causa. Alguien sabe si esto esta relacionado??? Ayuda por favor..
If you send outside of GSM Alfabet
other charters that this.
https://www.smsnetwork.org/default_alphabet.html
You need you use unicode for give UTF-8 signs but unicode can only support 70 charters if is a linked messess you have only 63 charters.
Nomaly frome UTF-8 pages some send inside of GSM alfabet use utf8_decode
I have developed both encoder and decoder of USSD commands and its respective response.
Thanks for this post, Justin, and for mentioning Unidecode / Unidecoder in your comment. It helped me find http://stackoverflow.com/a/23688057 which lists NodeJS / JavaScript ports for that Perl class to transliterate any UTF-8 character to ASCII / GSM compatible form).