Article summary
This was me at a recent sprint review meeting with the Local Orbit team:
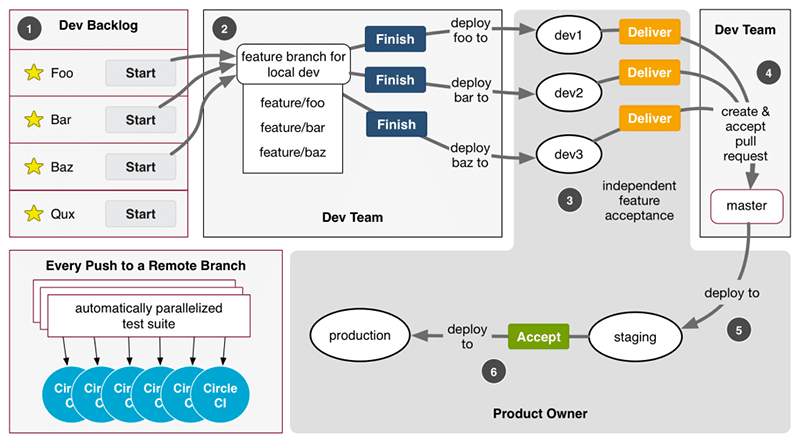
What really got me excited during this sprint was our success in implementing continuous delivery. For each feature we delivered, Anna was able to test and approve it before promoting the code, pushing to staging, and deploying to production. We went through this cycle several times this week, and Anna is now completely in control of what features roll into production, and when. This is a little out of the ordinary, and very, very cool!
Anna is the product manager for the Local Orbit platform. It’s her job to provide definition for–and set the priority of–all features in our Pivotal Tracker backlog. We work with Anna to create a development plan for each sprint and implement stories in priority order. Once they’re complete and accepted, she rolls the updates into production at her discretion… without developer intervention.
I was excited during the meeting not only because we’d achieved our goal of continuous delivery, but because the process and mechanisms we’d put in place were already paying off toward more important goals we had for our customer: transparency, empowerment and shared ownership.
Transparency
Anna can always be sure of what stories are ready to be staged, available in staging, or deployed to production… because she’s the one who put them there. We present completed features on several “dev” instances (in parallel, when necessary), which means code doesn’t get merged into the master until Anna tests and approves it. Using Github features like “compare/staging…master” and the Network graph, Anna can quickly observe what code in master has yet to be deployed to staging, and likewise observe the set of changes that have yet to roll from staging into production.
Empowerment
Not only can our product owner see what’s happening with her features, but Anna has the direct means to change the product. When she’s ready to deploy new features, she first executes a Pull Request to deploy them to staging, does some final testing, then uses another Pull Request to promote staging code into production. She can defer final deployment if she needs more time to test, or wants to avoid interrupting an important demo. Local Orbit is now self-sufficient with respect to deploying updates in the field.
Shared Ownership
It feels different, in quite a good way, to share the responsibility of deployment with a trusted product manager. Since Local Orbit is ultimately accountable for what its users experience, it only makes sense that Anna be the one to pull the trigger on the updates that go into the app… but there’s more to it than that. It’s no longer “that feature you deployed” or “they deployed”, but instead “we deployed.” I feel a little prouder of the features we’ve put into production this way; I feel like I’m contributing to the growth of a sustainable product and company.
Bonus: Efficiency
Though our primary goals were customer-oriented, we’ve already realized a notable side benefit of this process: more development time. Since smaller, focused deployments take less time to plan and test, and since Anna is now shouldering the deployment work, staging / production deployment events hardly affect development at all. We spend less time coordinating the content and timing of releases; we merely keep our eye on the CircleCI and Semaphore status reports to make sure things are still running smoothly. This time bonus came unlooked-for, as I had personally assumed that increased deployment frequency would come with increased time cost.
To sum it all up subjectively: Giving our cleint the keys to deployment has been gratifying and liberating–I highly recommend you try it on your own projects. Look for opportunities to empower your customers to own more and more of their development process, and to control their own destiny when deploying their product to their users. It may not seem easy (feats of technical wizardry, a committed product manager with a good head for details, supportive leadership) but when it comes together, it’s awesome!