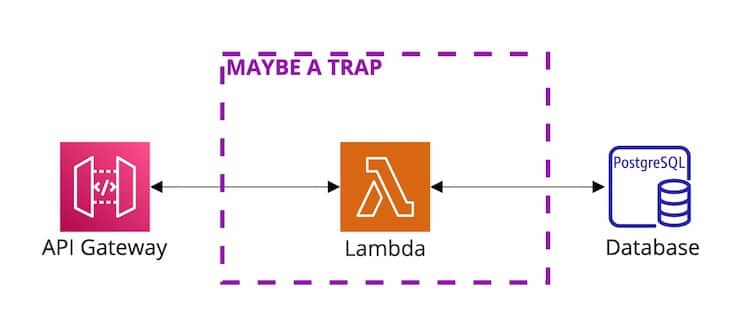
If you search for examples of cloud-deployed APIs, you’re sure to find many examples using an AWS Lambda to provide the computing power behind the API. But is this actually a good idea as so many examples and toolkits would lead us to believe? Or, is it an unfortunately naive example luring developers into a scaling trap? Let’s investigate.
How Lambda Handles Requests
Whether a Lambda is behind an API Gateway or AppSync resolver, or whether you’re invoking it directly, it will handle exactly one request at a time. AWS will spin up new Lambda instances as needed to handle additional parallel requests. Additionally, each Lambda instance can handle a sequence of many requests before it gets recycled by the service.
Starting up a new Lambda instance takes a few seconds. This increases the time for a response to be generated when a new Lambda instance is needed to handle a parallel request. The exact cold-start time depends on bundle size, which runtime is in use, instance size, and whether it needs access to resources in a VPC.
You’re only charged for the compute time used.
Lambda concurrency can be provisioned ahead of time to handle the increased load or limited to control the impact of a vast army of Lambda workers on other parts of the system. Requests that hit a concurrency limit will return errors. This means API clients will need to handle those failures and retries as appropriate.
The Downsides of Lambda
That scaling model isn’t inherently bad. But, we’ve run into some common downsides when using Lambdas as the compute behind a GraphQL or REST API. These downsides are especially noticeable when we’re building a relatively constant-use API and start seeing increases in activity. Most of the specific examples I include are based on Node.js because that’s what I’ve used most. However, the downside will apply to almost any Lambda.
Hitting Database Connection Limits
Most relational databases can handle a limited number of connections. For example, a db.t3.micro instance of RDS Postgres can handle up to ~80 connections. That’s surprisingly easy to hit when each parallel request uses a database connection and none of the usual database connection pooling mechanisms work. (Most need to run in the same process or at least on the same server, like Prisma.) AWS provides good recommendations for dealing with this, like using RDS Proxy or the Data API for Aurora Serverless. However, those will not work with all libraries and infrastructure plans.
Prisma uses prepared queries that don’t play well with RDS Proxy (you won’t get any benefit). Plus, past experiences with Aurora Serverless v1 steered us away from that for production use cases (but maybe v2 holds more promise). Options to mitigate these constraints include running a larger RDS instance to avoid connection limits, switching to a library that supports RDS Proxy, or moving away from Lambda as a compute provider for our API.
And Limits of Other Infrastructure
Relational databases aren’t the only place these types of limits come up. You need to ensure that other services can handle the parallelized loads that Lambda can generate.
Cold Start Time
I’ve seen cold start times for new Lambda instances reaching over 10 seconds, and a user will experience that delay unless Lambda concurrency is provisioned high enough to avoid it. That delay can be enough to push longer-running requests over the 29s limit for API Gateway requests.
Cost & Constraints of Provisioned Concurrency
Speaking of provisioned Lambda concurrency, you’re going to pay for that. The cost can exceed other types of provisioned compute capacity provided by EC2, Elastic Beanstalk, or Fargate. Additionally, there’s an account-level Lambda concurrency limit that each Lambda with provisioned capacity subtracts from and each running lambda instance contributes toward. So, care needs to be taken to increase that limit and avoid hitting it.
More Suitable Behavior
There’s something about a Node process handling exactly one request at a time that rubs me the wrong way. Maybe running Apache and mod_perl on bare-metal Linux servers back in the mid-2000s and later enjoying the simple scalability of hosting providers like Heroku spoiled me. But, I think we can find a solution that exhibits behavior that’s better suited to most APIs.
I’d like a solution that:
- can handle more than one concurrent request per scaling unit, so that it has a more robust base scale and provides more compute flexibility from the start.
- can scale up in response to load and avoid users experiencing slow responses.
- supports common database connection pooling mechanisms (Prisma, etc.).
- is still cost-effective.
- preserves a lot of optionality for running our application in different environments (local, automated tests, etc.).
We’ve started running our API compute as load-balanced Docker images via ECS and Fargate. Targeting Docker preserves a lot of flexibility and ECS and Fargate provide good control over the scaling and load balancing without needing to manage servers directly. A Node process running Express in a Docker container can handle many concurrent requests effectively. And, all the usual database tools are happy to help us with connection pooling (thanks, Prisma!). So far, we’re happier with this setup and how it avoids many of the problems we had with Lambda.
Using a Lambda
Lambda may still be a good candidate to back an API if it will have long periods of zero use to take advantage of the potential cost savings, long cold-start times are acceptable to hit, and the upper limits of the expected load won’t stress the rest of the architecture.
We still use Lambdas for some event-driven processes on the backend, like handling messages on an EventBrridge bus or processing files uploaded to S3. Even in these contexts, you need to be aware of the scaling model. In those cases, you should consider taking steps to add control over the scaling, like inserting an SQS queue between an EvetnBridge rule and Lambda meant to process the messages.