There’s a tried-and-true architecture that I’ve seen many times for supporting your web services and applications:
- PostgreSQL for data storage
- Redis for coordinating background job queues (and some limited atomic operations)
Redis is fantastic, but what if I told you that its most common use cases for this stack could actually be achieved using only PostgreSQL?
Use Case 1: Job Queuing
Perhaps the most common use of Redis I’ve seen is to coordinate dispatching of jobs from your web service to a pool of background workers. The concept is that you’d like to record the desire for some background job to be performed (perhaps with some input data) and to ensure that only one of your many background workers will pick it up. Redis helps with this because it provides a rich set of atomic operations for its data structures.
But since the introduction of version 9.5, PostgreSQL has a SKIP LOCKED option for the SELECT ... FOR ...statement (here’s the documentation). When this option is specified, PostgreSQL will just ignore any rows that would require waiting for a lock to be released.
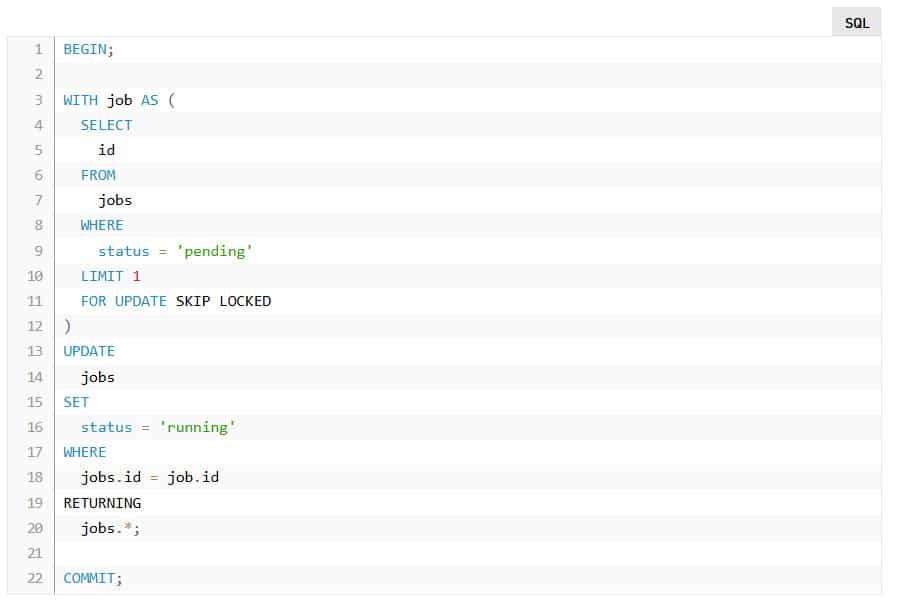
Consider this example from the perspective of a background worker:
BEGIN;
WITH job AS (
SELECT
id
FROM
jobs
WHERE
status = 'pending'
LIMIT 1
FOR UPDATE SKIP LOCKED
)
UPDATE
jobs
SET
status = 'running'
WHERE
jobs.id = job.id
RETURNING
jobs.*;
COMMIT;
By specifying FOR UPDATE SKIP LOCKED, a row-level lock is implicitly acquired for any rows returned from the SELECT. Further, because you specified SKIP LOCKED, there’s no chance of this statement blocking on another transaction. If there’s another job ready to be processed, it will be returned. There’s no concern about multiple workers running this command receiving the same row because of the row-level lock.
The biggest caveat for this technique is that, if you have a large number of workers trying to pull off this queue and a large number of jobs feeding them, they may spend some time stepping through jobs and trying to acquire a lock. In practice, most of the apps I’ve worked on have fewer than a dozen background workers, and the cost is not likely to be significant.
Use Case 2: Application Locks
Let’s imagine that you have a synchronization routine with a third-party service, and you only want one instance of it running for any given user across all server processes. This is another common application I’ve seen for Redis: distributed locking.
PostgreSQL can achieve this as well using its advisory locks. Advisory locks allow you to leverage the same locking engine PostgreSQL uses internally for your own application-defined purposes.
Use Case 3: Pub/Sub
I saved the coolest example for last: pushing events to your active clients. For example, say you need to notify a user that they have a new message available to read. Or perhaps you’d like to stream data to the client as it becomes available. Typically, web sockets are the transport layer for these events while Redis serves as the Pub/Sub engine.
However, since version 9, PostgreSQL also provides this functionality via the LISTEN and NOTIFY statements. Any PostgreSQL client can subscribe (LISTEN) to a particular message channel, which is just an arbitrary string. When any other client sends a message (NOTIFY) on that channel, all other subscribed clients will be notified. Optionally, a small message can be attached.
If you happen to be using Rails and ActionCable, using PostgreSQL is even supported out of the box.
Taking Full Advantage of PostgreSQL
Redis fundamentally fills a different niche than PostgreSQL and excels at things PostgreSQL doesn’t aspire to. Examples include caching data with TTLs and storing and manipulating ephemeral data.
However, PostgreSQL has a lot more capabilities than you may expect when you approach it from the perspective of just another SQL database or some mysterious entity that lives behind your ORM.
There’s a good chance that the things you’re using Redis for may actually be good tasks for PostgreSQL as well. It may be a worthy tradeoff to skip Redis and save on the operational costs and development complexity of relying on multiple data services.
Well explained Chris, thanks for the insights.
thank you so helpful !!
Aren’t you losing performance then (redis being in-memory store)?
Hi, Thanks for this great article !
I known a few implementation of message queue on top of Postgres in Python : https://gitlab.com/dalibo/dramatiq-pg and https://github.com/peopledoc/procrastinate to name a few. Also for ruby : https://github.com/que-rb/que.
Full disclosure, I maintain Dramatiq-pg. ;-)
Regards,
What about performance? Jobs pushing to redis is really fast and this will matter when you have to push jobs before giving a http response.
Good tips, we use PostgreSQL, but I would also be interested in the performance tradeoffs.
The main issue I see with advisory locks is
– you will likely eventually need or want to use a connection pooler like pgbouncer if your application grows
– session-based advisory locks don’t play nicely with such an approach, since they will be shared by any client sharing the same connection via pgbouncer, negative the purpose of the lock
I don’t think this means you shouldn’t use advisory locks, but this is a significant tradeoff.
I 100% agree with the opinion. Transaction-based advisory locks are not OK – we can’t open the transaction and keep it opened to achieve the pessimistic lock behavior. It is too expensive for Postgres.
Session-based advisory lock trade-offs are already perfectly described. I should just add one more note – Imagine you have to reload your server, so you have to close the connection. You’ll lose all your locking information, which will lead to the pessimistic lock feature failure.
Unfortunately, Advisory locks are not suitable for the user-defined (frontend-defined) pessimistic locking. Actually, at this stage, PostgreSQL is not suitable for the pessimistic locking feature at all (not scalable enough)
NOTIFY has char limit but Pub/Sub not.
About queuing dans PostgreSQL you must have a look at Procrastinate project. https://procrastinate.readthedocs.io/en/stable/