
Article summary
I monitor a handful of websites with some critical information on them. I also have a Synology NAS. Here’s how I created a pipeline for mirroring and archiving these key sites onto my NAS.
My goal for the website backups is to have zipped archives created once a week. The Synology task scheduler software can take care of the weekly jobs. I’ve also chosen to build my backup process on Docker, as Synology’s Docker plugin manages it nicely.
The Process
For any given site, the backup and archival pipeline goes like this:
- Use HTTrack to mirror the website to the local filesystem.
- Bundle the mirrored content into a zip with 7-Zip.
- Move the zip artifact to my backup directory.
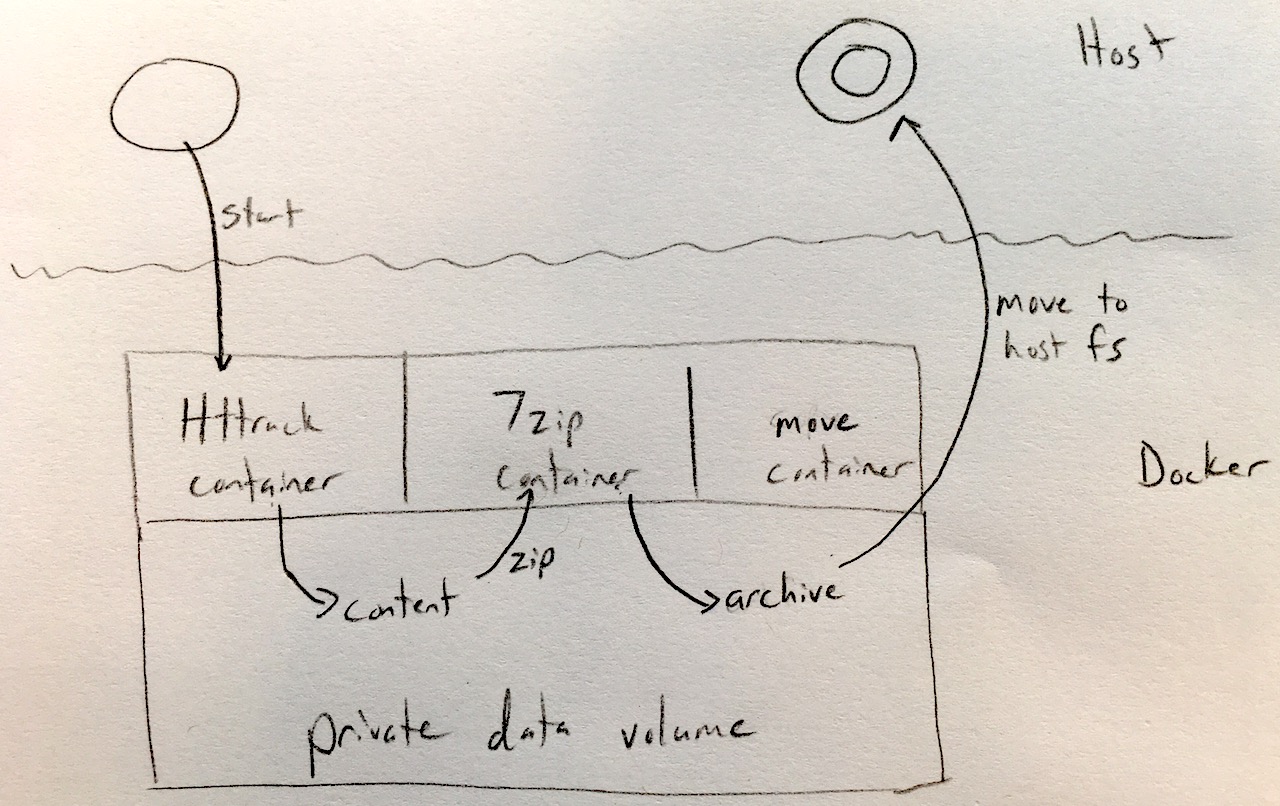
To facilitate the above, I’ve created a shell script for the Synology task scheduler to run. The script:
- Uses the
ralfbs/httrackimage to mirror the website to a local, private Docker volume. - Uses the
crazy-max/7zipimage to compress the website content into a single artifact. - Uses the
Alpine Linux 3.8image to move the artifact to the host filesystem.
The script itself is not particularly interesting–it’s essentially three docker run commands for the above steps, plus a few lines of supporting code for configuration.
Tradeoffs and Considerations
No tool like this is perfect, and I’ve chosen to make some compromises and arbitrary decisions.
Using Docker
My use of Docker for this purpose is arguably inappropriate; a script running local utilities would be just fine.
Ultimately, I chose to go with Docker for two reasons:
- It’s a self-contained way of running arbitrary packages on the Synology NAS.
- It’s given me a chance to fiddle with Docker.
Use of a private volume instead of the host filesystem
Private volumes are probably overkill for this application, but I like using them for two reasons:
- I like the way the private volume helps keep intermediate artifacts self-contained within the environment of the script. There are no leftover intermediate files sitting in my way.
- It’s given me a chance to fiddle with private volumes in Docker.
In both cases, I feel like reason #2 justifies my decisions.
Conclusion
Overall, I’m pretty happy with the way my mirroring and archival pipeline turned out. Not only does it serve an important need, but it gave me some experience with Docker.
More importantly, the experience gives me confidence in speaking with my colleagues about Docker day-to-day.
Would u mind sharing your code?